{kind=link}
monday, september 20, 2021
it's always the last day of the festival
you're always packing to go home
[https] posted by dozens on August 18, 2022
Rhythm Nation causes a vulnerability
[https] posted by lucidiot on August 18, 2022
[https] posted by acdw on August 18, 2022
[https] posted by lucidiot on August 18, 2022
I recently stumbled on the language Nim. And while normally I am wont to enjoy a space delineated language I am really digging Nim. It's a little statically typed, statically compiling language. You can extend the built in libraries without thrashing them, which gives you a quasi-lispy hack-ability, and it's easy enough to read. Okay, maybe a little less easy to read than say Golang, but it's good enough, some {} wouldn't kill anyone. But seriously it's a cool little language!
Probably more exciting than that though is that it's fast, and it builds wicked small binaries. The compiler is nice and verbose and errors out early, so you don't have to guess which of the 18 errors the compiler reported come from the one actual issue (lookin at you Golang). And it can do some weird things like compile to Javascript! I don't know when I'd use that, but I feel like that's got to be a pretty useful feature right?
I kind of just dove right into Nim after reading the Learn Nim in Y Minutes guide, it was good enough to start reading code, but I found myself quickly reading through the official Nim tutorial guides to get a better understanding of how the language works. It's just different enough that you sort of need to grok the literature that's out there, but once you do it's a breeze to work with. I ended up immediately rewriting my little battery percentage calculator for my Droid. See I had previously written a really quick on in Golang, but the binary for it is 1.9m, and I'm nearly the point where my poor Droid is running out of space. All of these 6MB+ Golang binaries (or the 30MB+ common lisp ones) that do really stupidly simple things are really unnecessary here. Sure 1.9M isn't a big deal, but, well just look I feel like I'm really not wasting space with Nim.
batt|>> du -h *-battery
1.9M go-battery
88K nim-battery
Shaved off more than a megabyte! And it's also ever so fractionally faster than the Golang version too.
batt|>> time ./go-battery
79%
real 0m 0.03s
user 0m 0.00s
sys 0m 0.00s
batt|>> time ./nim-battery
79.0%
real 0m 0.00s
user 0m 0.00s
sys 0m 0.00s
Think of what I'll do with that fractional second back and that whole 1MB of disk space! The possibilities are limitless! Err, I guess technically they're limited to 1MB and a part of a second, but in aggregate there's amazing things here I'm sure.
Side by side, the Nim version ends up only being 15 lines of code, and the Golang version is 28. I'd say the Golang version is easier to read without knowing Golang though, it's kind of the intent of the language after all. But I can't be more pleased with this simple example.
package main
/* Report droid battery, semi accurately-ish.
Author: Will Sinatra, License: GPLv3 */
import (
"fmt"
"io/ioutil"
"log"
"strconv"
)
func main() {
max, min := 4351000, 3100000
/* this sys/class file returns the string "int\
" instead of just int */
nowbyte, err := ioutil.ReadFile("/sys/class/power_supply/battery/voltage_now")
/*we have to truncate the \
with a slice of the array */
nowslice := nowbyte[0:7]
now, _ := strconv.Atoi(string(nowslice))
if err != nil {
log.Fatal(err)
}
perc := (100 - ((max - now) * 100)/(max - min))
fmt.Println(strconv.Itoa(perc)+"%")
}
import strutils, std/math
#Expand proc & to concat float & strings
proc `&` (f: float, s:string) : string = $f & s
#calculate rough battery percentage from Droid4 voltage_now file
proc batt() : float =
let
max = 4351000
min = 3100000
now = readFile("/sys/class/power_supply/battery/voltage_now").strip().parseInt()
perc = (100 - ((max - now) * 100) / (max - min))
return round(perc)
echo batt() & "%"
Obviously the Golang version does do a little bit more than the Nim one, there's better error handling, but it's really not much different. This was a simple enough starting point for me to jump into a little bit of a larger small program to get a feeling for the library ecosystem. Nim comes with a package manager called nimble, and it works as you'd expect. It's pretty close to how Golang's packaging system works, though my experience with it thus far is utterly cursory. I didn't have to reach for a lot of community libraries because just like Golang Nim has a robust built selection of libraries. All of this just means that when I went to go make a multipart form upload POST helper for my paste service I didn't need to do anything crazy.
import os, httpclient, mimetypes, strutils
#nim c -d:ssl -d:release lcp.nim
#Paste a file to https://lambdacreate.com/paste
proc lcp() : string =
var
client = newHttpClient()
data = newMultipartData()
#Set lexical variables for configuration & auth
let
mimes = newMimetypes() # <- Instantiates mimetypes
home = getEnv("HOME") # <- Grabs /home/username
conf = home & "/.config/lcp.conf" # <- Concats path to config file
crypt = readFile(conf).strip() # <- Extract crypt key for /paste auth
#If we get more or less than 1 argument error
if paramCount() < 1:
return "A file must be specified for upload"
if paramCount() > 1:
return "Only one file is expected."
#-F key="crypt"
data["key"] = $crypt
#-F upload=@file
data.addFiles({"upload": paramStr(1)}, mimeDb = mimes)
#http POST, strip new line on return
client.postContent("https://lambdacreate.com/paste", multipart=data).strip()
echo lcp()
32 little lines of Nim later and I've got a function paste helper, and once it's compiled it comes out to a whopping 504K, absolutely minuscule. Especially considering I'm just importing whole libraries instead of picking out the functions I actually need to import into the program. Prior attempts to do this with Fennel failed miserably, I think primarily because I couldn't get luassl to format the POST payload correctly. But Nim? No problem, in fact the the official documentation for std/httpclient describes exactly how to make a multi-part POST!
Hopefully these little examples got you curious, or even better excited, to give Nim a try. For me this fits a really nice niche where I want a batteries included, very well documented language that will be fast and absolutely minuscule. I'll probably leave my prototyping to Golang, but Nim's definitely finding a home in my tool-chain, especially considering that after only a few hours of poking and very cursory reading I'm already rewriting some of my existing tools, I think I definitely had an "Ooh shiny" moment with Nim. And I tend to get very much stuck on those.
[https] posted by wsinatra on August 17, 2022
[https] posted by m455 on August 17, 2022
tenpo ko: a universal timezone clock
[http] posted by dozens on August 17, 2022
Hank explains the new US climate law, and why we can be optimistic about it.
[https] posted by kindrobot on August 15, 2022
Over the past two years I've absolutely fallen in love with Golang. It's a great (not so little) language that Google has been shepherding, but really we have the brilliant minds behind Plan9 to thank for it. All of that might just upset some people, not everyone's a big G fan after all, but I don't mind when the tool fits the job. For me, that job is typically prototyping. In my line of work being able to move fast and get a function example or MVP out is a huge step, and the faster I can do it the better. Obviously I still want to be able to use that prototype, kick the tires and such what, but so long as I'm not worried about the size and to some degree the performance I will readily and happily reach for Golang.
You might think to yourself, what does Golang have going that couldn't be accomplished in Python, or pretty much any language you could cherry pick out the list. And my answer to you would be nothing I suppose. But it has some bells and whistles which make me reach for it before the likes of Python. (And for those of you who know me, while I do actively avoid reaching for Python at all, it has its time and place too. Just not on my machines..). Anyways, those features. Golang's a lot like C, you can compile it down to a tiny static binary, a few megabytes in size. You can natively cross compile it to multiple different operating systems. The community and core libraries are absolutely bananas, nearly a library for anything you could need or want. And the compiler is so obtusely opinionated that you have to try to write buggy code!
All of this makes it a joy to work with. I know that something I write in Golang can compile and run on Alpine Linux, or Ubuntu, or Arch, but also Windows or MacOS, and funnily enough even Plan9! And while that last one might seem silly, I frequently find myself utilizing the same tooling on my Plan9 terminals that I reach for when I have my droid. At $work I use it to quickly build backend services, little glue bits that extract and ex-filtrate data, or keep an eye on things that can't be tied into the larger monitoring picture. And I've even written a couple of silly HTTP monitoring/utility services like ATSRV, PNTP, fServ, and auskultanto. In order that's a /proc info server, a poorman's NTP server, a file download/upload server, and a configurable status system. You get the picture I hope, you can kind of throw together these neat little micro services that can compile for anything, run anywhere, and due to the availability of the language's libraries be built in a somewhat trivial effort/timeframe.
Once again, yes I could just do this with Fennel/Lua or Common Lisp, but it just isn't as fuss free. And as much as I love Common Lisp, the binaries end up being 30mb+, so I can't complain in the slightest about a 6mb Golang binary. Also, have you tried using Fennel on Plan9? It's stuck on an ancient version and needs some love before that's going to be a viable option.
My latest prototype utility is another HTTP micro server, it's a little configurable custom check system, meant to be thrown behind a load balancer like the AWS ALB so you can define a custom health check. Normally not a necessary step, but sometimes just checking to see if Apache is serving something at a path isn't enough, so auskultanto (listener in Esperanto) listens in for those little health checks and returns up to date information about, well, whatever you decide to configure really! Here let me show you.
~|>> curl http://127.0.0.1:8092/command?name=uptime
{"Stdout":" 21:10:43 up 3:39, 0 users, load average: 1.17, 0.95, 1.17\
","Stderr":"","Timestamp":"2022-08-15 21:10:43.007781982 -0400 EDT m=+23.979705812"}
~|>> curl http://127.0.0.1:8092/service?name=sshd
{"Stdout":" * status: started\
","Stderr":"","Timestamp":"2022-08-15 21:11:44.101013183 -0400 EDT m=+85.072937013"}
~|>> curl http://127.0.0.1:8092/script?name=test.sh
{"Stdout":"neuromancer\
","Stderr":"","Timestamp":"2022-08-15 21:11:59.156463623 -0400 EDT m=+100.128387453"}
Auskultanto exposes three endpoints, command, service, and script, and for each one it returns a little JSON blob with the stdout/stderr of the command chosen and a timestamp from the execution. Really simple, and pretty nifty! And you're probably thinking, this is absolutely horrible, it's remote code execution over HTTP! Well.. yes and no. Lets look at the config file.
Log: auskultanto.log
ScriptDir: /var/auskultanto/scripts/
Init: openrc
# /service?name=sshd
Services:
- sshd
- iptables
# /command?name="netstat%20-tlpn"
# /command?name=uptime
Commands:
- uptime
- hostname
- netstat -tlpn
# /script?name="test.sh"
Scripts:
- test.sh
Nothing crazy, but you'll note that under each endpoint we list out our valid checks, each as a single line under the endpoint. And while it might not stick out, it's perfectly fine to include multi argument commands such as netstat -tlpn, auskultanto will be happy to consume that. The only caveat is that you should escape your spaces with %20, it is a URL after all.
Not too shabby for a prototype right? We can define a couple of simple commands, write a quick script, or look for a service status and then write a little match using the JSON output. But what happens if we run a command that isn't configured? Obviously with something like this the very first thing we should try is a /command?name=whoami, or maybe a /command?name=sudo%20whoami. And if those work, we definitely need to try a /command?name=sudo%20rm%20-rf$20/%2A right?
Whenever an endpoint is queried, auskultanto records the endpoint, what the name of the request was, and then any error messages related to that event. And obviously a timestamp, because it wouldn't be much of a log otherwise would it? Here's the log from the example above:
2022/08/15 21:10:43 Queried: /command
2022/08/15 21:10:43 Command key: uptime
2022/08/15 21:11:43 Queried: /service
2022/08/15 21:11:43 Service key: sshd
2022/08/15 21:11:59 Queried: /script
2022/08/15 21:11:59 Script key: test.sh
And this is what happens when we start trying to run things that aren't configured. Auskultanto isn't particularly fond of it. Lets try a whole bunch of unconfigured things!
2022/08/15 21:31:03 Queried: /service
2022/08/15 21:31:03 Service key: wildfly
2022/08/15 21:31:03 wildfly is not a configured service.
2022/08/15 21:31:24 Queried: /command
2022/08/15 21:31:24 Command key: sudo whoami
2022/08/15 21:31:24 sudo whoami is not a configured command
2022/08/15 21:42:28 Queried: /command
2022/08/15 21:42:28 Command key: uptime&&whoami
2022/08/15 21:42:28 uptime&&whoami is not a configured command.
2022/08/16 01:53:00 Queried: /command
2022/08/16 01:53:00 Command key: rm -rf /*
2022/08/16 01:53:00 rm -rf /* is not a configured command.
2022/08/16 01:52:01 Queried: /script
2022/08/16 01:52:01 Script key: test.sh; rm -rf /*
2022/08/16 01:52:01 test.sh; rm -rf /* is not a configured script.
From the client side, when auskultanto doesn't recognize a command it silently logs the information like above, and doesn't return anything to the client. I may change this in the future, but my logic is that if there's no return people are less likely to poke at it. Adding more information, such as the requesting IP address is a solid next step for this little tool, so that iptables rules could be automated based on bad requests. If it ends up getting abused.
Once again, this tool is just a prototype, something thrown together in a couple of hours to see if it can even be done. I'm proud of how resilient and flexible it seems right out the box. I'll continue to work at the idea and expand on the functionality in the future, but for now enjoy a toy monitoring system.
~dozens has started a podcast with tildeverse citizens as its guests. Since podcasts are fully backed by RSS, well there is an RSS feed available. I helped him iron out some details on the feed, since I had never toyed with RSS feeds for podcasts before and wanted to look at them a bit more in-depth. Maybe if I get enough experience helping casakhstan people set up their podcast feeds, I will write about it here…
C Isn't A Programming Language Anymore
[https] posted by dozens on August 15, 2022
[https] posted by acdw on August 14, 2022
I’ve subscribed to friends’ weeds (really dozens for now—hi dozens!) under a hidden link on my planet.acdw.net thing. I hope this is okay with everyone.
Hi, acdw! Thanks for sharing your secret weed alligator aggregator. I’m glad that you have a way to read weeds now!
Also read dozen’s bit on ed, the standard text editor. I also am using ed now! Thanks 12s. This is fun.
Yess, I hope the ed craze sweeps the nation. Or at least the weedsphere. Glad you’re having fun. I might maybe have over-intellectualized what the writing process was like for me. It’s a slower more methodical process for me. This response, for example, I wanted to write out rather quickly. So I’m writing in vim.
The other thing that makes me interested in ed that I didn’t write about is using it for shell scripts. There are some examples in the Ed Mastery book about using ed to manipulate some files, which looked cool.
Something like this:
for x in files do
ed $x << EOE
1
i
BLA BLA BLA
.
wq
EOE
doneOH btw dozens you can rlwrap ed and it’s nice.
I did use rlwrap! I like having command history for the most part. But yeah that does provide some better cursor control.
Whoa, just read the manpage on readline and it is much more configurable than I ever realized..
ed is the standard editor
Some time ago I read a blog post in which the author was describing their process for authoring content for the web. Specifically they were talking about their personal method of writing markdown.
The trick, they said, is to write paragraphs made of individual sentences (themselves made of words), each one on its own line. One sentence per line. Paragraphs separated by a blank line.
This trick works because writing one sentence per line means that for each line, there is only one sentence. You can easily reorder sentences, join them, etc. And you can more easily see the length of sentences, so that you can vary length. Follow a long sentence with a few shorter ones. Allow the reader to rest and relax. Reading long sentences is taxing, after all.
The thing that makes this work for composing thoughts is that markdown converters will turn all of your lines into a single HTML paragraph. Paragraphs in turn are separated by a blank line.
The process of writing and revising in this fashion is of course referred to as ‘line editing’. Which means that a ‘line editor’ must be uniquely suited to the task.
Which is why I am writing this post in a line editor named ed. Ed is the standard text editor.
I have a little computing device that I refer to as a ‘typewriter’. It is essentially a keyboard and an e-ink display. It really is typewriter-esque.
When the device first came out, it had no editing capabilities whatsoever. Besides just backspacing and starting your thought over again. But it had no movable cursor. No way of moving through the text. It does now. But it didn’t then.
Its editing capabilties remain rudimentary. And writing in ed reminds me of it in a certain way.
I’ve used vim most of my life, and so I am very familiar and comfortable with modal editing. But using that typewriter, and using ed, makes me realize that I never fully engaged in modal thinking or modal writing. For so long as I had a visual editor, modality was a feature of the editor and not of my mind. I was able to continue to write and edit, to think and revise at the same time.
On the other hand, ed (and the typewriter) has afforded me my first experience with internalized modal editing. Now I experience a true separation of writing and thinking versus simuntaneous editing and revising.
I’ve already written elsewhere about how the typewriter lead me to adopt a “write now, revise later” workflow in which I just brain dumped, got the ideas out with little care for or attention to spelling or grammar. Editing and revising it for clarity, consiceness, and cohesion only came later, in a different setting and on the laptop.
Writing in ed gives me the same feeling. First and foremost come the thoughts, the feelings, the ideas. The act of wrangling thought into words. Later I’ll edit some lines.
So what is it really like to write in ed? It’s fine. I definitely recommend the one-sentence-per-line trick. You don’t want to be trying to edit a paragraph length line.
Writing is no real problem. It’s editing that can be tricky. There’s no real cursor control at all. You instead must rely on manual search and replace, which isn’t that bad at all in practice. Otherwise you can change the entire line and type it in over again.
Ultimately, I’d say any inconvenience is well worth the way it changes how you think.
When ed was created, a lot of people worked on computers that were basically a keyboard and a printer. No monitor. The workflow included a lot of pencil and paper. You would write out your program ahead of time, and then type it into the computer, and see if it ran. While you were typing, you could have the computer print out the last couple of lines to see if you made an error or not. At the end of the day, it was common to print out the whole program and take it home and make corrections to it on paper. The next day you could come back to the program loaded up on the computer and make corrections to those lines with a line editor.
A line editor like ed.
That’s the story I told my partner when they asked me what I was writing about just now. I told them that this week I started using a text editor from the 1970s designed to be used with a headless computer with nothing but a printer for output. For fun.
Learning ed feels like discovering my ancestry. Like I said earlier, I have used vim pretty much my entire computing life. Many vim commands come directly from ed, via ex and vi. For example, search and replace, the global command, write and quit, global search and replace, search, join lines, read from or write to shell commands.
Here are some other things that ed pioneered, influenced, or popularized: or popularized:
regular expressions
grep
sed
ex, vi, and vim
Does ed still deserve a place in modern computing and writing? I don’t know, maybe. It is refreshing in a certain way to write in ed. It’s about constraints. It is refreshing to write and revise this way in the same way it is to code for a fantasy console. Adhering to arbitrary constraints. Like writing haiku.
There is no vimrc to get distracted by. No config to waste time tweaking. All there is to do is just write. There is nothing else.
I do think that my little e-ink typewriter might be both more fun and more useful if I had the option to write and edit in ed. Now that I’ve spent some time with it, I do think that a line based editor is both more useful and more elegant than the primative character based editor it has.
How can Santa keep his lists when the GDPR is around?
[https] posted by lucidiot on August 13, 2022
writing an xml schema validator in… xml
[https] posted by lucidiot on August 11, 2022
[https] posted by acdw on August 11, 2022
[https] posted by dozens on August 11, 2022
IRC bot written in Retro Forth
[http] posted by wsinatra on August 11, 2022
Gemini Server written in Retro Forth
[http] posted by wsinatra on August 11, 2022
[https] posted by m455 on August 11, 2022
[https] posted by lucidiot on August 10, 2022
leprd.space: free web hosting for hobbyists
[https] posted by m455 on August 10, 2022
[https] posted by m455 on August 09, 2022
acdw has a new authoring tool and markup language!
[https] posted by m455 on August 09, 2022
[https] posted by wsinatra on August 08, 2022
[https] posted by wsinatra on August 08, 2022
[https] posted by dozens on August 08, 2022
2022-08-08 00:00
I've been pretty busy lately, so I haven't had a lot of time to explore computers, which is what I love doing. In the last few months, I've been trying to fight back against busyness by writing a new website generator after everyone goes to bed. I can't recommend doing this, because it gets exhausting after a while, but it gives me my kicks and makes me happy.
My old website generator, wg, was a wrapper around
Pandoc, and was written in Fennel. I used separate
fennel scripts to generate a list of posts and an RSS feed as post-thoughts to
the website generator. Also, I didn't know about
Wireguard when I programmed wg. For those of you
who don't know, Wireguard uses the command-line name wg, so it was best that I
didn't compete with that haha.
I still love Pandoc and Fennel, but I wanted to try to program something that had the following features:
{{variables}} in Markdown files with values that are declared in
the configuration fileI also wanted an excuse to make a bigger programming project in Chicken Scheme haha.
I think what I'm most proud of for this project is that I was able to implement
string templates. For example, the {{im-an-example}} in the text below would be
replaced with the value that corresponds to the im-an-example key in a config.scm
file.
Hey there, this a sentence, and my name is {{im-an-example}}.
Though, this wasn't that easy.
First, I had to implement string replacement... Okay, okay, string replacement
exists in Chicken Scheme using the string-translate, string-translate*,
irregex-replace, or irregex-replace/all procedures, but where's the fun in
using those? I don't get to build anything!
My first step was to write a procedure that replaced the first occurrence of a
string. I ended up using the string-append, substring, and string-length
procedures to implement the following procedure:
(define (str-replace str from-str to-str)
(let ((from-index (string-contains str from-str)))
(if from-index
(string-append (substring str 0 from-index)
to-str
(substring str
(+ from-index (string-length from-str))
(string-length str)))
str)))
This isn't very useful if you plan on having several of the same placeholder
values in one string, so I also needed to write a procedure to replace all
occurrences of the string. It will drop into an infinite loop if I try to
replace l with ll, but this is personal programming, not some software that
needs to be battle tested, so I settled with my implementation below:
(define (str-replace-all str from-str to-str)
(let ((from-index (string-contains str from-str)))
(if from-index
(let ((rest-of-string (substring str
(+ from-index (string-length from-str))
(string-length str))))
(string-append (substring str 0 from-index)
to-str
(str-replace-all rest-of-string from-str to-str)))
str)))
Next, I needed somehow to take a list of pairs, convert the first item in each
pair to a string, and then surround the string with {{ and }}, so it
resembles one of the placeholder values that I mentioned earlier. After it
changed the first element in each pair, I then took the first element of each
pair, searched for it in the provided string, and then replaced it with the
second element, using the str-replace-all procedure to ensure all instances of
that placeholder were replaced.
I actually ended up having to split this algorithm into two procedures to keep things maintainable for myself in case I needed to go back to fix or update the code around this functionality. Here are those two procedures:
(define (key->mustached-key pair)
(if (pair? pair)
(let* ((key (symbol->string (car pair)))
(mustached-key (string-append "{{" key "}}"))
(value (cadr pair)))
`(,mustached-key ,value))
pair))
(define (string-populate str kv-replacements)
(if (null? kv-replacements)
str
(let* ((mustached-keys (map key->mustached-key kv-replacements))
(first-pair (car mustached-keys))
(key (car first-pair))
(val (cadr first-pair)))
(string-populate
(str-replace-all str key val)
(cdr kv-replacements)))))
This ended up helping me get really good at quasiquoting in Scheme as well!
Apart from the string-populate procedure, and the core procedures that it's
built on, most of the other features aren't anything special, though I did enjoy
that I can just read arbitrary s-expressions from a string using Scheme's read
procedure. The read procedure made it super easy to read a configuration file
that was all s-expressions. For example, all I needed to do was load an
alist
in a file with the following procedure:
(define (load-config-file)
(if (file-exists? config-file)
(with-input-from-file config-file read)
#f))
This procedure returns a quoted alist, so I wrote the following helper procedure to read it:
(define (get alist key)
(if (and (pair? alist)
(pair? (car alist))
(symbol? key))
(cadr (assq key alist))
alist))
Functional programming purists will hate me for this, but this then allowed me
set a globally mutated variable with (set! config-data (load-config-file)),
and then read the variable with a (get config-data 'source-dir).
I've been using this method for reading and reloading configuration files for other projects as well, so that was a great learning experience.
As for generating my list of posts and RSS feed, all I needed to do was parse
each Markdown file in a directory that's specified in the configuration file.
To make things easy, the title of a post was extracted from the first line of a
file, which should always be a Markdown H1 heading. I would then take the
Markdown heading, for example, # hey i'm a heading, and remove the number sign
and space proceeding the number sign, leaving me with hey i'm a heading.
The remaining string would be used as the title for each post in the list of
posts page, and the title of each RSS item. The way I generated links for my
list of posts page was by converting the source path from, as an example,
<source-dir>/path/to/post.md to
https://<domain>/path/to/post.html.
Because dates are pretty important to RSS feeds, although not required, if
you're following the spec, I chose to put dates on the third line of each post,
in the format of yyyy-mm-dd, so I could convert yyyy-mm-dd to a number that
resembled yyyymmdd, and then reverse sort by each number, resulting in a
"latest post first, oldest post last" order.
To kind of finish this off, I think one of the major annoyances was converting
all fenced code blocks to use indentation instead, because Chicken Scheme's
lowdown egg replicates what the original Markdown parser does. That, and
replacing all of my Pandoc-centric Markdown stuff such as its Markdown version
of <div> blocks:
:::{.im-a-class}
hey im a div
:::
The upside to using old school, feature-less Markdown is that the Markdown for my website will work on most Markdown parsers I guess? Haha.
The downside to using the lowdown Markdown parser is that heading anchors aren't generated, so all of my links to heading anchors are broken, but I got to have fun with programming in Scheme at least? Plus, this isn't my professional website, so things are allowed to be broken here, and I don't want to get rid of old posts because they bring back good programming adventure memories for me.
I figured this blog could use a new post, so here it is!
Have a good one!
If you want to check out the source code for my new website generator, you can view it here.
While Gitea's 1.16.0 release added support for user feeds, it was laching the feeds for repositories, organizations, releases and commits. The 1.17.0 release adds support for feeds on repositories and adds support for feeds on organizations, but the feed for releases, the most well-known and most commonly used feed on GitHub, is still missing.
As mentioned earlier when I talked about the 1.16.0 release, the feeds are accessible either by setting the Accept header to application/rss+xml or application/atom+xml when requesting a user, an organization or a repository's URL, or by appending .rss or .atom to the username, repository name or organization name. Some examples:
I hope that we will see the feeds for releases in the next release, so that Gitea adds the one missing feature to make package maintainers happy.
By the way, the RSS feed for the RSRSSS repo could be called the Really Simple RSRSSS Repository Syndication feed, or RSRSRSSSRS.
[https] posted by wsinatra on August 05, 2022
[https] posted by mio on August 04, 2022
[https] posted by acdw on August 04, 2022
[https] posted by wsinatra on August 04, 2022
Wazuh, an open source SIEM platform
[https] posted by wsinatra on August 03, 2022
[http] posted by m455 on August 03, 2022
cursed software bugs, with rss feed
[https] posted by lucidiot on August 03, 2022
We can't send email more than 500 miles
[https] posted by wsinatra on August 03, 2022
if you type in your pw, it will show as stars
[http] posted by wsinatra on August 03, 2022
[https] posted by wsinatra on August 03, 2022
the french police is not a backup.
[https] posted by lucidiot on August 03, 2022
Imagine an embedded media player, right here. Pretty ain't it?
I started a podcast, and after re-recording this episode at least a dozen times I've finally got something I can put out into the world! There's very little focus this episode, in fact I'd go so far as to say I spent 20 minutes rambling about how excited I am to actually be going forward with this crazy idea. But this is definitely the hardest part.
I've rebuilt my website just to accommodate this new type of media, written helper tools and scripts to produce the audio, rss feeds, and recording. Everything from the first second to the "go live" publishing has been hand curated on my handy dandy droid4. And it's with all of these simple hacky glue bits that I've hacked together this episode for you. So sit back, and hopefully enjoy the first of many episodes of the Low Tech Radio Gazette!
If anyone listens and would like to give feedback, please reach out to me at wpsinatra@gmail.com. I'm very actively trying to refine the quality of the podcast, so constructive criticism is welcomed.
[https] posted by lucidiot on August 03, 2022
smol Windows, Palm OS and OSX apps
[https] posted by lucidiot on August 03, 2022
Interneting is Hard - webdev tutorials for beginners
[https] posted by mio on August 02, 2022
a 'quick and dirty' literate programming tool in awk
[https] posted by acdw on August 02, 2022
Wikipedia is a quality resource
[https] posted by lucidiot on August 01, 2022
The free and healthy typeface for bread and butter use
[http] posted by dozens on August 01, 2022
Open letter to Google Security team from a librarian (warning: GDocs link)
[https] posted by acdw on August 01, 2022
Simple Firewalls with iptables
[http] posted by wsinatra on July 29, 2022
The Old School Computer Challenge Rules!
[https] posted by wsinatra on July 29, 2022
[https] posted by wsinatra on July 29, 2022
[https] posted by wsinatra on July 29, 2022
[https] posted by wsinatra on July 29, 2022
Recutils, GOOPS and virtual slots
[https] posted by dozens on July 28, 2022
[https] posted by wsinatra on July 28, 2022
charmbracelet goodness for shell scripts without go
[https] posted by dozens on July 28, 2022
[https] posted by marcus on July 28, 2022
Velocipedia - bicycles based on people's attempts to draw them from memory
[https] posted by mio on July 28, 2022
Zero to chiptune in one hour (2017)
[https] posted by mio on July 28, 2022
The Ultimate Amiga 500 Talk: Amiga Hardware Design and Programming (2015)
[https] posted by mio on July 28, 2022
The Ultimate Game Boy Talk (2016)
[https] posted by mio on July 28, 2022
[https] posted by acdw on July 27, 2022
[https] posted by acdw on July 27, 2022
[https] posted by mio on July 26, 2022
Rocking the Web Bloat: Modern Gopher, Gemini and the Small Internet
[https] posted by mio on July 26, 2022
[https] posted by acdw on July 26, 2022
[https] posted by wsinatra on July 26, 2022
rewrite it in rust, but in french
[https] posted by lucidiot on July 26, 2022
look, it’s tomasino!
We talk about a great many things including, of course, tildes, and also vim vs. emacs, linux and bsd, gopher and gemini, games, minimalism, community, magic, and more!
Your secret message for this episode is:
zdv nhwb h uxd fe lfwb jnhejb dl mvbttfem xnfjn lfembct f nhwb aqhjbk kdxe hek xfeefem h efjb tvcacftbStuff we talked about on the show
birthday song
A while back I talked about documenting some of the things I've been learning from my LFCE studying, I think if I've gotten to a point where I feel comfortable writing about a topic then I'm likely prepared to test on that subject too. So let's talk a little bit about iptables!
Iptables is simply a firewall software, and unfortunately it gets a reputation for being complicated and confusing. It's definitely not a point and click solution like you get with UFW or Firewalld, but it powers both of those solutions, so why shouldn't you learn it? Even something like Alpine's Awall is powered by iptables, and while I have a personal affinity for Awall, iptables is still the root; if you understand how it works it doesn't much matter what you're dealing with. You can easily figure out how a UFW, Firewalld, Awall, or any other iptables backed firewall software works, and that includes plenty of the off the shelf enterprise solutions out there. Mikrotik's for example work this way, and their custom tooling follows very closely alongside iptables.
Additionally there are some really neat features you can leverage with iptables, such as rate-limiting by local user, much like you'd do inside of something like a Fortigate's NGFW. Nifty, and free!
Here's an example of a really simple workstation firewall. Characteristically its operation is simple, it allows any sort of outbound traffic, and only allows certain types of inbound traffic. I'd say this is likely the simplest and most relatable configuration to frame iptables with. Any laptop, desktop, or even something esoteric like the droid can be considered a workstation if you're working on it regularly. Typically you want anything you do on that system to be sanctioned outwards, but you want to more granularly control which ports are open and what can access the resources on your workstation. Unlike a server the expectation is that traffic originates outwards to multiple points, and inbound traffic is rare and should meet expected parameters.
*filter
:INPUT DROP [0:0]
:FORWARD DROP [0:0]
:OUTPUT ACCEPT [0:0]
#Route established and related traffic
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -i lo -j ACCEPT
#Allow SSH
-A INPUT -i wlan0 -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
-A INPUT -i wlan0 -p udp -m state --state NEW -m udp --dport 60000:61000 -j ACCEPT
#Allow Lapis Dev
-A INPUT -s 192.168.88.0/24 -i wlan0 -p tcp -m state --state NEW -m tcp --dport 8080 -j ACCEPT
#Allow fserv
-A INPUT -i wlan0 -p tcp -m state --state NEW -m tcp --dport 8090 -j ACCEPT
#Allow PNTP
-A INPUT -i wlan0 -p tcp -m state --state NEW -m tcp --dport 8091 -j ACCEPT
#Drop other unlisted input, drop forwards, accept output
-A INPUT -j DROP
-A FORWARD -j DROP
-A OUTPUT -j ACCEPT
COMMIT
Nice and short, maybe not as easy to grok as the pretty UFW output, but I promise it's not that bad either. These rules are in the format that iptables-save expects, you can pretty much append "sudo iptables" to any of the -A CHAIN rules there and it'll add that specific rule temporarily to your iptables ruleset in the specified chain.
*filter
:INPUT DROP [0:0]
:FORWARD DROP [0:0]
:OUTPUT ACCEPT [0:0]
At the very front we define our filter table it contains three chains by default, these chains essentially store our rules and let us think about our firewall in a consistent way. The default chains are pretty straight forward to work with, INPUT is anything coming into the firewall, FORWARD is anything that is going through our firewall, and OUTPUT is anything leaving the firewall. A quick glance at the full ruleset and you'll note that we use all three chains. Lets look at just the top and bottom of our ruleset to see those in action.
#Route established and related traffic
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -i lo -j ACCEPT
#Drop other unlisted input, drop forwards, accept output
-A INPUT -j DROP
-A FORWARD -j DROP
-A OUTPUT -j ACCEPT
COMMIT
Since iptables rules are processed from the top down (unless a JUMP to a specific chain is defined) it's easy to build out traffic exclusions. The tail end of the droid's ruleset is precisely this, you can read it as follows:
So if our ruleset only defined these items it would ACCEPT any sort of OUTBOUND traffic, anything that uses the interface lo, and DROP any INBOUND or FORWARD packets, effectively blocking the outside world but allow our own traffic to tentatively find its way into the wild unknown. This is actually a solid baseline for a simple but effective firewall. But we can't just shut ourselves off from the world right? If you're like me you really need to be able to SSH into every system you own, or maybe you need to expose an HTTP port for testing a project.
#Allow SSH
-A INPUT -i wlan0 -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
Fortunately those use cases are easy to define, the above example can be read as follows. Append to the INPUT chain to allow any NEW traffic coming into interface wlan0 of packet type TCP bound for port 22. We specifically bind this to the NEW state because we allow ESTABLISHED and RELATED traffic at the top, so it's redundant to look for anything else to allow new SSH connections.
#Allow MOSH
-A INPUT -i wlan0 -p udp -m state --state NEW -m udp --dport 60000:61000 -j ACCEPT
Some applications require multiple ports to function, such as Mobile Shell or Mosh for short. That application looks for a UDP port inbetween 60000-61000, so we give out --dport arg a range of min:max to work with, but otherwise the rule is exactly the same as a the simpler SSH rule.
#Allow Lapis Dev
-A INPUT -s 192.168.88.0/24 -i wlan0 -p tcp -m state --state NEW -m tcp --dport 8080 -j ACCEPT
No perhaps we want to filter based on where traffic is coming from, for instance I like to run the Lapis application for my blog when I'm traveling. I can always access it on 127.0.0.1 because we allow all traffic from -i lo, but I don't need random strangers on a public wifi network to see my in-dev work. Adding a -s 192.168.88.0/24 restricts the INPUT to any addresses in that subnet. So anything on my home LAN can access that port, but nothing else. Obviously that's not perfect design, there easily could be a public wifi network that uses that subnet, as it's Mikrtoik's default DHCP address range. You should also consider your firewall a single layer in a multi-layer defence!
The syntax is a little weird, but if you break each argument of the rule down it starts to make sense. Here's how I read these things.
-A INPUT
Append to chain INPUT
-s 192.168.88.0/24
Any traffic with source IP of subnet 192.168.88.0/24
-i wlan0
Inbound from interface wlan0
-p tcp
That is TCP protocol traffic
-m state --state NEW
And is NEW traffic
-m tcp --dport 8080
Which is TCP traffic destined to port 8080
-j ACCEPT
If all of that checks out, jump to the ACCEPT chain, and push the traffic through.
Phew, yeah there's a reason that people look at iptables and think "I can't make heds or tails of this" it's extremely verbose, and once you move out of simple usecases like this and into something like a full blown NATing firewall configuration it can be a little scary. But that verbosity is your friend! These rules state very explicitly what they do and do not do. And each flag can be read as a specific check that's performed on the traffic. I'm honestly very happy to have moved away from UFW for my systems and now maintain iptables rules for all of the systems in my homelab. The flat file configuration nature works perfectly for simple provisioning, and the full rulesets can be revisioned in git for long term maintenance.
I'll revisit this topic sometime in the future so we can work through desigining a NATing firewall with iptables. There's a lot of dependent systems there too, so that will give us a chance to dig into DHCPD, and BIND at very least. I've got an idea in mind, it just needs to be fleshed out before I actually bring it to the blog.
[https] posted by elioat on July 22, 2022
[https] posted by acdw on July 21, 2022
diff output from git can be hard to read. luckily there’s a nice tool bundled with git that can help us out.
enter diff-highlight, a little perl script found in git’s contrib directory.
from its own documentation:
[diff-highlight] post-processes the line-oriented diff, finds pairs of lines, and highlights the differening segments.
diff-highlight is shipped in a default git install but it needs to be added to your $PATH. here’s how to do it on debian:
$ sudo make -C /usr/share/doc/git/contrib/diff-highlight
$ sudo ln -s /usr/share/doc/git/contrib/diff-highlight/diff-highlight /usr/local/bin/
now you can pipe git’s diff output to to diff-highlight to get a better view of what actually changed.
git diff | diff-highlight
optionally, you can configure git to use it all the time. add the following to your ~/.gitconfig:
[pager]
log = diff-highlight | less
show = diff-highlight | less
diff = diff-highlight | less
see the documentation for more usage tips!
How to setup aescbc secstore on plan9
[https] posted by wsinatra on July 21, 2022
Jenga tower dice alternate for sttrpgs
[https] posted by wsinatra on July 21, 2022
[https] posted by wsinatra on July 21, 2022
[https] posted by acdw on July 20, 2022
[https] posted by acdw on July 19, 2022
[https] posted by dozens on July 19, 2022
nofetch, a new fetch tool by acdw
[https] posted by acdw on July 18, 2022
[https] posted by acdw on July 18, 2022
It's that time of the year again, we've hit the Old School Computer challenge again! If you're not aware of what the OSC is, take a look at Solene's blog for more information but the gist of it is that for a week you're limiting your technological usage to a single core system with 512MB of RAM or less. Additionally this year we're tracking our network time, with a maximum of online time of 1 hour per day, to emulate that costly dial-up experience.
I had a lot of fun doing this last year, it was really cool to put an old system to use, and I continued to use my Viliv as an IRC bot host after the end of the challenge. Unfortunately its battery died and I cannot for the life of me find a replacement, so it's back in the junk drawer for the time being. This year I'm rocking new old gear, and putting myself well outside of my comfort zone by running 9front a fork of Plan9 for the duration of the challenge. To add a fun twist to all of this, I'll be in Canada for the duration of the challenge with no backup systems, and no access to LTE. For better or worse I'm locked in on going as offline as is humanly possible here!
Alright brass tacks first, I'm using an Acer Aspire One D255, that's a netbook from 2010 with an Intel Atom N550, 1GB of RAM, and a 32GB SSD. It has a full RJ45 port, VGA, 3 USB 2.0, and 2 3.5mm jacks, plus a 54mbps wlan nic. It's about 10in with a little 3/4 keyboard and a 1024x600 resolution (that super nice weird netbook res). That's enough ports and features to scare off an Apple hardware engineer! Right off the bat though you'll note that that Atom processor is a 4 thread CPU, and I've got 2x the RAM for the challenge. I'm restricting downwards using software limitations, but I think long term there may be room for this netbook in my travel kit.
Because I'm traveling during the challenge, I started the challenge a little early and spent the day prior to the challenge starting preparing for the system for the trip. While I blew entirely through my hour online limit immediately, it was somewhat necessary so that I could get the netbook working. Before doing this installation I had only done 2 Plan9 setups, both of them for CPU servers, which is somewhat different from setting up a traveling Terminal system. I also needed to get drivers because neither the wireless nic nor the rj45 nic worked out of the box. Between figuring out the installation, and getting networking, encryption, a local aescbc secstore for Factotum, and my git repos + some music synced I think it took me 4-5 hours total. More or less I immediately used up my allotment for the trip just to make sure I could run acme on a netbook. Oof, oh well it's day 0, we'll try for better during the trip! Lets dig into what was learned in that time.
I'd of gotten very not far without the documentation the community has created and the man pages in 9Front. The information that's available is somewhat sparse, and very quirky, but it's that way because most of the information you're looking for is already in the man pages and is curated in a very professional way inside the OS itself. What's not in the guides is more personal flavor that's created by avid 9 users. I appreciate the communities hard work here, I got all of my bases covered thanks to their hard work. Here's everything I referenced online during the installation, in case anyone wants to consult the specifics for their own installation.
Really the only piece of information that I had to piece together for myself was the plan9.ini configuration file, which fortunately I'm really familiar with configuring after setting up my CPU server. If you ever need to cripple your system for fun and profit, you just need to drop the following lines into your plan9.ini file. Accessing the plan9.ini is an exercise left up to the reader (hint: it's in the documentation linked above!). Specifically these arguments in order disable multi-thread support, set a limit of 1 cpu core, and set the maximum memory to 512M.
*nomp=1
*ncpu=1
*maxmem=512M
And then some other simple QoL scripts to make things a little easier on me day to day. For example I took inspiration from the wifi init script/decrytion prompt that 9labs came up with and found out I could just extend my $home/lib/profile script to additionally prompt to decrypt my aescbc secstore and then populate the Factotum during my login, which additionally meant that authentication to pre-existing wireless networks became as simple as passing the network name to the init script during the boot process! Here's the full terminal case from my profile, if you're familiar with plan9 you'll note that this is extremely minimal modification, but it's really just that easy, the initwifi command comes from 9labs.
case terminal
if(! webcookies >[2]/dev/null)
webcookies -f /tmp/webcookies
webfs
plumber
echo -n accelerated > '#m/mousectl'
echo -n 'res 3' > '#m/mousectl'
prompt=('term% ' ' ')
if(test -f $home/lib/fact.keys)
auth/aescbc -d < $home/lib/fact.keys | read -m > /mnt/factotum/ctl
initwifi
fn term%{ $* }
rio -i riostart
At the end of working through these I had a working system I could travel with, and I'm honestly quite happy that with just a few hours of work I had an encrypted system, with an offline secstore for my keys, working SSH out to my servers, a bunch of local git repos. Really everything I needed was right there in a nice secure installation. And it ran wicked fast despite having a software crippled configuration, well until you try and compile a new kernel. That took a good 30min, but I just won't do that until later on.
Oh and if anyone is searching for how to SSH on Plan9, the syntax is a bit different, you need to do it this way.
ssh username@tcp!192.168.88.101!20022
Truthfully this day was very quiet. I was getting ready for the flight out. I was slammed at work, and when I actually had free time after work I spent it prepping. When I did use my netbook I tried to get IRC working, but was unable to get ircrc to connect to my friends ergo instance, I defaulted to just running weechat on a server for the interim. Having figured out Factotum and aescbc before starting the challenge meant that I could SSH in and out to all of my Linux boxes without fuss, which let me build and troubleshoot the installation of the new web engine on my blog. I have an LXD cluster at home and I worked "offline" as much as possible troubleshooting bugs in my Lapis application before using the the last of my time to actually push the changes live.
The git workflow on plan9 is a little awkward. I find myself trying to type git add . when it's git/add file, and git/commit requires a file to be called with it so I constantly have to retype it. Despite this the workflow is very usable. I had no problems modifying etlua templates, Lua code, and even Fennel! I thought maybe I could test my fennel code on the netbook even, but the version of Fennel that's patched for 9 is 0.3.0, and we're on 1.1.0 currently, which won't work well. I might see if I can get the patches they added up-streamed to the official repo, it would be nice to have fennel available on Plan9.
During this entire process, and previously on day 0, I found that the netbook heats up massively. The fan inside the netbook may be malfunctioning. Even running with software restrictions it puts out a ton of heat. And the brand-ish new 6 cell battery I have for it only lasts about 3 hours on a charge, and it takes 2hrs to give it that juice. I'm slightly worried this will hinder my ability to use it during travel. I'm flying from Boston > Montreal > Vancouver > Kelowna, so I've got a solid 12hrs of travel to deal with, and I'll want to actually use the netbook while I'm in flight. There's literally no better time to crank out a blog post than when you're strapped into a seat with absolutely zero distractions. And normally if I had my Droid with me I'd work on Sola a little bit, or maybe tkts, but since both of those projects are in Fennel it's a no go.
Golang has better support though, so during day 2 I tried to compile that on the netbook. With the software restraints it quickly OOM'd the system and it crashed pretty hard. No harm done at all, but I won't be doing any Golang work. That said, software written in Golang that's compiled on Linux runs beautifully. I have a little HTTP file server + ingest-er called fServ that runs beautifully on 9Front. I used it to transfer a couple of gigs of music and podcasts to the system from my NAS right before departing. I've got a 6am flight out, so last minute entertainment here!
Finally traveling, and officially starting the hard part of the challenge. True to my word I left with only the plan9 netbook for my trip. I have my kobo with me, just in case, and obviously my cellphone, but without coverage in Canada this is pretty much it. My flight was canceled early, and I got shuffled around to a mid morning flight, unfortunately I was at the airport extremely early nonetheless. I got to watch the sunrise in Boston Logan. Fortunately since people are sparse that 4am I got prime seating at the gate and was able to plug in and crank out a blog post on using iptables. Oddly it was a very peaceful event. Despite my lack of sleep and frustration the muted color scheme of Plan9 was honestly very enjoyable. And working inside acme to write etlua is a breeze. No need for syntax highlighting or anything, just simple HTML and Lua.

I kept with the blogging theme the rest of the trip. I was running on low fumes and didn't feel up to trying to actually tinker with the netbook. It's too much of a fuss to try and get airport wifi working on something like Plan9 since it requires a JavaScript webauth session, and I couldn't get netsurf running before my trip. I'm really not upset by this though, without a way to readily connect to the network I was able to just focus and be productive. I know once I find an easier to work with network I'll be able to push my offline changes to Gitlab and I might even be able to make that iptables post live during the trip.
During that time I made ample use of zuke, it's a fantastic audio player, I find it very easy to work with and the man pages are extremely clear and concise. I had no fuss building curated playlists while I was in the middle of blogging. It worked equally well for listening to podcasts which made the leg out to Vancouver a little better. I also found a bug in my site management utility that's currently causing my RSS feeds to generate with broken date format strings. I think I would have found the broken section a little easier with syntax highlighting, but I think dark mode terminals would actually be harder on my eyes.
What strikes me most thus far is that if your use case is simple, or very focused, then Plan9 gives you just enough tooling to get that work done. Nothing else to get in the way. Sure it can run a couple of simple emulators and doom, but things are a little bit out of the way. You have to hunt for them and that makes them that much more out of your reach. By not having an RSS feed to pull up and refresh 8 times, or IRC to lurk on, or a functioning web browser to fiddly about with my choices are very limited. I can use this system to connect to my CPU server at home potentially, or to my VPS or Tilde Town, or I can hunker down and be productive. Plus the color scheme is very honestly easy on the eyes. I've had my fair share of sleepless nights and long haul travels, but I when I'm dealing with that I typically can't stand to stare at a screen for too long. By comparison I find no issue with this netbook. Perhaps it's the light brightness of the old screen combined with the mellow color scheme, whatever it is I really like it.
Oh by the way, Plan9 mile high club? Guarantee I'm the only person on this flight with such an eclectic rig.

The only other thing that's immediately notable is that this particular netbook gets absurdly hot, even when restricted to a single core it's uncomfortably hot! I had honestly forgotten what that was like, I have a Dell laptop with an intel core 2 duo in it during college that always felt like this. It was mildly uncomfortable keeping the netbook on my lap because of that. Thankfully as you can see it fits extremely well on the fold down tray (and the seat in front of me was leaned back so it was exta tight!), so no discomfort for me!
And it turns out that after getting into Kelowna for my work trip I neither had much free time to participate in the OSC, nor any broken infrastructure to desperately attempt to fix with only a Plan9 netbook at hand. I'm somewhat upset that I didn't get to do much more with this little thing, but at the same time utterly thrilled that the challenge wasn't disruptive. It's all for the best though, I had absolutely no cell service once I was out in Kelowna, so even if I wanted to abandon the data challenge I couldn't.
Instead of putting miles on the old netbook, I picked up Infinity Beach by Jack McDevitt and chewed through it in my spare time.
I'm hopeful that this little challenge will pop back up next year. I've had a lot of fun with it both years. So much so that I'm wrapping up this blog post from my netbook despite having my droid readily at hand!
There doesn't seem to be anything strange, to me, about traveling with old gear. I think all in this netbook cost me $50 inclusive of a set of new 6 cell batteries for it. It's cheap enough that if it gets broken, stolen, or lost that I won't be upset. Plan9 is quirky, but has the necessary security features to make me want to bring it abroad. And honestly when I travel the things I really want to do while in the air is blog. I enjoy writing these posts, and if I have an hour or two at a hotel it's very easy to crank out a blog post. Something very low resource, an electronic typewriter almost, is a welcomed addition to my collection. I certainly won't be shipping this netbook off to the junk pile now that the challenge is over!
On Plan9 itself I think I'm still just getting comfortable with it. I don't think I'm very effective in it, not in the same sense that I am with Linux. I needed a lot of documentation, and some step by step guides to get to a point where I felt I could even commit to doing the challenge on this thing. I honestly love that, the feeling of something new and the child like wonder of learning about it piece by piece is a super fun experience. The entire OS really is well put together, the way that the Factotum works is particularly fascinating to me. And the fact that you can very quickly modify the system init via a simple RC script is a great idea, and feels very much like modifying .xinit scripts.
I don't know that I would be able to do all of my programming on a Plan9 system, yet. I miss syntax highlighting, it really helps when looking at lisp code, but that's such a small complaint to have, I feel like I'm fishing for it. Acme is a great editor, eloquently designed, and extremely easy to use. I was immediately productive, and there's something to this mouse driven environment that does honestly work in a way that is both intuitive and easy to use. I've already caught myself trying to do mouse chords on my Ubuntu laptop at work, to a great amount of dismay. I would happily steal the entire Rio environment to use on Linux in a heartbeat, it really does just work.
Anyways, this is getting a bit rambly I think. If you've read through and are on the edge of giving Plan9 a shot, I would say go for it. If you're curious you'll discover an interesting and unique environment to explore. If you're thinking about turning that ancient netbook into a usable system, Plan9 is a great fit for it too! And if you're here from the Old School Computer challenge, then thanks for the read and the awesome challenge again this year!
static site hosting from tildegit repos
[https] posted by dozens on July 16, 2022
writing and running a bbs on a Macintosh plus
[https] posted by elioat on July 15, 2022
(posted wednesday, july 13, 2022)
i'll start by saying that it's
better after a while
for you at least
the dimensions of your
life, they do expand
it's worse, too, and
sometimes for years on end
there are things ahead
that are going to destroy parts of you
there are things ahead
that are going to tear at the whole frame
of the world you inhabit
one of the things that life is
is a series of losses
that you never quite recover from
and in all that,
you're going to fuck up a lot
you'll learn most of what you learn
the hard way
you'll fail altogether
to learn far too much
but all the same you'll make some friends,
fall in love more than once
and in more than one way
wake up on some mornings
to find yourself strong and able
maybe fear will always be with you, and
far too much of it
but the walls that arise in your mind
between you and some imagined truer self
they fall away with time
along, maybe, with the idea that
there's any truer self to be found.
[https] posted by dozens on July 13, 2022
Check out eli:
This is a super fun show! We talk about making the internet quieter and weirder, and games, and all kinds of stuff.
Check it out!
Your secret message for this episode is:
eofgq ytb mtj iofedwdj ntth ytb ht cg eod itjrh ethfy kdlfbvd ce icrr sfqd eod itjrh eofe sblo kdeedj f urfld fgh id frr gddh fv sblo odru fv id lfg nde

Stuff we talked about on the show
[https] posted by acdw on July 12, 2022
relative vs absolute urls in rss content hell
[https] posted by m455 on July 12, 2022
web-based system administration for Unix
[https] posted by m455 on July 11, 2022
stylish text generator (all of the early msn messenger nickname ascii art you need)
[https] posted by m455 on July 11, 2022

In reply to: A simple mess
This is also something people keep getting wrong about Markdown as originally presented. Markdown isn’t a format. It’s a convenience tool that helps you write some of the boringest and commonest parts of HTML easier, and you can easily drop into more wonky HTML at any time.
Yes yes yes yes yes yes!
Markdown isn’t supposed to be a markup language unto itself. It is an intermediary format that usually targets HTML as it’s final form.
[https] posted by acdw on July 08, 2022
[https] posted by acdw on July 08, 2022
How to build a web app with Clack/Lack (Common Lisp)
[https] posted by elioat on July 08, 2022
Apparently, a new search engine disgned with devs in mind.
[https] posted by marcus on July 07, 2022
[https] posted by acdw on July 07, 2022
[https] posted by mio on July 07, 2022
[https] posted by dozens on July 07, 2022
[https] posted by acdw on July 06, 2022
[https] posted by acdw on July 06, 2022
I remember the days when Kicks Condor used to update regularly. I miss those days.
For a while every post seemed to unearth some new, yet weirder corner of the little internet (maybe not yet the smol web).
There are folks doing similar web archeology…I do some of it myself…but no one does it like Kicks was doing it; there was often a feeling of unknown, but ulterior motive behind the curation — bits building towards a cohesive something.
Perhaps Kicks got lost in the web — out there still?
running wordpress with sqlite is quick, easy, and can be much less system administration load as it eliminates the need for a separate database process running.
this site is currently running with sqlite using aaemnnosttv’s drop-in.
/var/www)/var/www/yoursite/wp-content/adjust configs as needed. this is the live config for this site wptest.bhh.sh.
snippets/ssl/bhh.sh just includes the block from certbot that points to the right cert and key.
server {
listen 80;
server_name wptest.bhh.sh;
return 307 https://$server_name$request_uri;
}
server {
listen 443 ssl;
server_name wptest.bhh.sh;
include snippets/ssl/bhh.sh;
index index.php index.html;
root /var/www/wptest.bhh.sh;
client_max_body_size 100M;
location / {
try_files $uri $uri/ /index.php?$args;
}
location = /favicon.ico {
log_not_found off;
access_log off;
}
location = /robots.txt {
allow all;
log_not_found off;
access_log off;
}
location ~* wp-config.php {
deny all;
}
location ~ \.php$ {
include snippets/fastcgi-php.conf;
fastcgi_intercept_errors on;
fastcgi_pass unix:/run/php/php7.4-fpm.sock;
}
location ~* \.(js|css|png|jpg|jpeg|gif|ico)$ {
expires max;
log_not_found off;
}
location ~ /\.ht {
deny all;
}
}
[https] posted by elioat on July 06, 2022
[https] posted by dozens on July 05, 2022
[https] posted by elioat on July 05, 2022
It feels like it's been a while since I've written anything for the blog, the last post has been up since I did my Tildewhirl interview back in April and there's been nothing but silence here since then. That's not because I haven't wanted to post, I started working on capturing some tkts development, and I've had a couple of friends ask for tutorials on using iptables and packaging things. I'm really excited to get that feedback and write those posts, I just haven't been able to!
That begs the question, why not? Well the way that lambdacreate was designed initially was essentially me fumbling around with Lua and Lapis and just shoving everything that sort of worked into a docker container and calling it a day. The packages I relied on at the time weren't well maintained in Alpine, I really had no clue how to design a website let alone a somewhat dynamic web application, so I more or less hacked around these limitations using a bit of administrative magic and the result was the blog up until this point. It should look the same as before, but now we're way more functional! I no longer need to rebuild an x86_64 docker container just to post a new blog post, I can work solely with flat text files and lua and manage everything the old fashioned way. That's potentially what I should have done to begin with.
See the biggest issue with the design was the creation of the container itself, like the last post explained, most of my computer is done on an old armv7 system. It's took weak to build containers, even if they're not cross compiled, heck I tried to get qemu to run on the droid just for the heck of it and it couldn't even handle launching a VM in a reasonable time frame. The point is, that tooling is just too heavy for what I use day to day. Previously that meant digging out a different computer, like my Asus netbook which has a N4000 Celeron in it, just to make an already written post live. If I'm traveling that means everything grinds to a halt and there's no posts because I typically only bring my droid with me out and about. Major pain.
I guess what I'm trying to say is I de-over-engineered my blog, bye bye docker, hello old school administration! But that doesn't mean we've gone off the reserve and migrated to a static site generate, oh no, this is the same great Lua on Lapis dynamically generated content we started with, I'm just holding the tool correctly this time.
If you're on mobile you'll probably need to scroll to the bottom of the page, otherwise I'm sure you noticed the changes on the right hand bar. I've added a number of new routes to the site to handle blog post, archiving, podcasts, and projects. Some of that is familiar, plenty of it is new, and some of it was supposed to work from the onset but it took me two years to properly implement. I'll let you click around and explore the changes to the site by yourself, lets talk about Lapis and how all of this works.
In Lapis your web application is a collection of lua scripts that get executed by OpenResty. From a 1000ft view the core of that is a file called app.lua that Lapis loads with all of its various dependencies just like any lua runtime. Your routes leverage a Lapis internal called Lapis.Application which has an OO style implementation. All of this just means that your Lapis application is a collection of supporting lua libraries and app:function("route", "uri" function()) calls. Here's the index function for Lambdacreate, it'll make things clearer.
app:match("index", "/", function(self)
--Table of last 10 blog posts
self.archive = lcpost.getLast(10)
--The last published post
self.latest = lcpost.getPost(lcpost.getLatest())
--Last update of published post
self.timestamp = lcpost.getUpdated(lcpost.getLatest())
self.shows = lcpod.getShows()
--Table of projects
self.projects = lcproj.getArchive()
self.internal_layout = "index"
return { render = true, layout = "layout" }
end)
When you visit https://lambdacreate.com the Lapis application matches the HTTP request to the "index" route, which triggers a cascade of functions to internally gather information. Note the self variable here, the function that the route triggers has a self = {} var, that we attach named values to. These self variables are accessible inside of the etlua templating engine, which is what we use to do something with all of this information. These templates are part of the layout variable in the return call, we return the output of the route function to Lapis, which renders the layout template with the values from self. In Lambdacreate I use a global layout.etlua file, and then an internal_layout self variable to change the inner content.
This may make more sense if you look at the full template alongside the explanation, layout.etlua can be found here, and index.etlua can be found here.
Inside of layout.etlua we have a render function call that takes the value of the self.internal_layout and renders it's content. It essentially nests that etlua template into the layout.etlua template so the self variables are shared inside of that internally rendered template. Since self.internal_layout = "index", we render the body block of the website to the contents of the index template.
< render("views." .. internal_layout) >
That index.etlua file looks like this in full, you can see we're calling even more templates to render inside of that, but you get the gist. Anything inside of self is referential inside of etlua. I had to convert the HTML tags to paranthesis, because it kept breaking my etlua template rendering. Hopefully it's clear enoug.
(div class="row")
(div class="leftcolumn")
(div class="post")
(% render("views.posts." .. latest.id) %)
(/div)
(/div)
(div class="rightcolumn")
(div class="card")
(h3)Bio(/h3)
(% render("views.about") %)
(/div)
(div class="card")
(h3)Recent Posts:(/h3)
(ul class="list")
(% for k, v in pairs(archive) do %)
(% local route = "https://lambdacreate.com/posts/" .. v.id %)
(li)(a href="(%= build_url(route, { key = v.id }) %)")(%= v.title )(/)(/li)
(% end %)
(/ul)
(h3)(a href="(%= build_url('archive/post') )")Post Archive(/a)(/h3)
(/div)
(% render("views.shows") %)
(% render("views.dev") %)
(/div)
(/div)
What's really cool, is the Recent Posts segment, it's a lua function nested into the template itself. All it does is build a route by iterating over a table of information that gets passed by the self.archive variable. What this means is that the we only have to define the Recent Posts once as this function, every time we add a new post to the database the site will re-render the page the next time it's visited. No need to rebuild, reload, etc. Most of the templates that get rendered by layout or inside of index operate like this! We just need to know where to look.
So now that you know a bit about the templates, you can probably guess that our blog posts (and podcast episodes!) are generated the same way, but where are we fetching all of this information from? Well previously we stored all of our post information in a file called posts.lua, and it was a big old lua table filled with keys and values. Things haven't changed too much from that design honestly, we're still passing all of the information needed to render a route to Lapis as a table, however we're storing and managing that information in an Sqlite3 database! Lets look at lcpost.getLast(10) in the index route.
--Return a table of the last X records
function lcpost.getLast(num)
local db = sql.open("lc.db")
local stmt = db:prepare("SELECT id,title FROM posts ORDER BY id DESC LIMIT :limit")
local info = {}
stmt:bind_names({limit = num})
for row in stmt:nrows() do
table.insert(info, row)
end
stmt:finalize()
return info
end
That seems straight forward right? We select the id and title from our posts table, sort the output, and limit it to whatever variable we pass to the function. Then for each row returned from the SELECT we insert the values into a table called info and return it. The table we get from the select looks like this, and is what we iterate over in our Recent Posts route generation.
{
{ id = 35, title = "Truly using Lapis"},
{ id = 34, title = "The Infamous Droid"},
}
There's more complexity here than just hand typing a lua table, but the exact same logic and generation code works despite that complexity. The ability to coerce values into tables means we can more or less store things however we desire.
That's pretty simple, etlua gives us an easy way to populate HTML wire-frames with dynamically changing data, and Lapis gives us a nice interface for passing that information inwards to the rendering service. This provides a really clean way of thinking about how the website works, based on the above you can infer that when your visit https://lambdacreate.com/post/1, that it does a SELECT from posts where id = 1; and then returns that table above to populate the template. Dead simple design.
For the podcasts and archival information it gets a little bit more complicated, but I think you'll agree that it's still just as easy to understand. Here lets look at /archive routing, since it touches on the complexity of /podcast routing too.
--Blog posts/Podcast episode archive lists
app:match("/archive/:type(/:show)", function(self)
if self.params.type == "post" then
--Table of all posts
self.archive = lcpost.getArchive()
self.timestamp = {}
self.internal_layout = "post_archive"
return { render = true, layout = "layout" }
elseif self.params.type == "podcast" then
--Specified show information
self.show = lcpod.getShow(self.params.show)
--Table of all episodes in the show
self.archive = lcpod.getArchive(self.params.show)
self.timestamp = {}
self.internal_layout = "podcast_archive"
return { render = true, layout = "layout" }
else
--Redirect to e404 if the archive type doesn't exist
return { redirect_to = self:url_for("404") }
end
end)
Just like out index route, we use app:match to check the url of an HTTP request. Here that match is a little fuzzy, it'll match any of the following correctly.
Neat! We have one function that's capable of routing archival information for blog posts, and two different podcasts! If you try and go to /archive/podcast or /archive/podcast/something-that-doesnt-exist, it'll also force route you to a 404 page, so technically there's a fourth route hidden in there too. All of this works by matching the values passed in the url via the self.params value.
In Lapis when you visit /archive/podcast/droidcast the values of the url are saved in self.params vars named as the values in the app:match(route) segment. So for the /archive function we have two named variables :type and :show. If you visits /archive/post, then self.params.types == "post", and for /archive/podcast/droidcast self.params.type == "podcast" and self.params.show == "droidcast". After that render is handled inside an if statement to direct the request to the right set of functions and render the correct templates.
More simply, you can visualize it like this.
https://lambdacreate.com/archive/podcast/droidcast
-> self.params = { route = "archive", type = "podcast", show = "droidcast" }
Still with me? We're almost done, and if you're still reading then I think this is potentially the most interesting part of it all. To figure out how to get all of this to work correctly I've added a paste service to Lambdacreate. It's meant for internal use only (sorry!), but it has the most complicated route handling of anything else on the site.
I'm going to focus on the Lapis routing, if you're curious about the lcauth script you can find it here.For the purpose of discussing here, just know that it takes values passed via self.params and queries a database to determine if they exist, then returns true or false back to the Lapis application.
--Paste Service
--curl -v -F key="key" -F upload=@argtest.fnl https://lambdacreate.com/paste
app:match("paste", "/paste(/:file)", respond_to({
GET = function(self)
--This GET allows us to share the same name space as our POST
--static/paste - nginx:nginx 0755
--static/paste/file - nginx:nginx 0640
return
end,
POST = function(self)
--Check authorization of POST
local authn = lcauth.validate(self.params.key)
if authn == true then
--Upload a file to paste directory
local tmp = lcpaste.save(self.params.upload.content, self.params.upload.filename)
--Return the paste url
return {
render = false,
layout = false,
self:build_url() .. "/paste/" .. tmp .. "\
"
}
else
--Return access denied
return {
render = false,
layout = false,
"Access Denied\
"
}
end
end,
}))
For /paste we have both GET and POST handling, everything else we've discussed has only has GET handling. Fortunately in Lapis they work exactly the same way, and we can use the same route functions to render both requests. It works more or less like this:
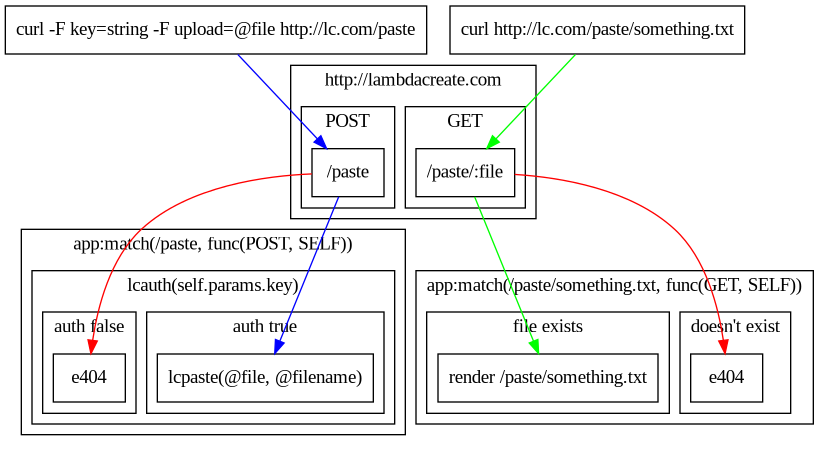
When you visit https://lambdacreate.com/paste/something.txt, Lapis drops into the GET specific function and returns a route to /paste/something.txt, internally this is just a static file serve and directs to /static/paste/something.txt. Once something is pasted it's up there and accessible. I don't currently have an archive of pasted things, but I'm considering adding a paste type to the archive routing. Otherwise GET for /paste is boring, it's dead simple nginx static file serving.
All the real magic happens in the POST function. When you POST to lambdacreate.com/paste it checks for the existence of a few values, first and foremost an authorization key. If that key is supplied and matches a good one in the database, then the actual lcpaste function is invoked and it pulls the file and the name of the file from self.params. Once the file is "pasted" a /paste/filename url is returned and you can view the file there. Otherwise if the key is bad, it returns an e404 and a Not Authorized message to the user, and nothing gets written to the site.
I'm pretty excited about this new feature, it should mean that I'll be able to paste to lambdacreate from any of my devices all with their own unique key. If I ever need to remove authorization for a device then it becomes a simple matter of removing the authorization info from the database. Obviously there's nothing unique about that, but I like knowing that I can control when and if things get pasted while still being able to generally route any requests to those pasted files.
Whew! I think that's about it! This has taken a little bit to get going, according to git I pushed the first commit in the series of these changes on May 18th, so about a month and a half of on and off work in mostly 1-2hr sessions to get this together. Feels really good since this has been something I've had to my TODO since I launched the blog a couple of years ago. Honestly rebuilding those docker containers got old fast. If you've read to the end thanks for sticking with me!
If you're curious about Lapis and want to try it out, Leafo has some pretty amazing documentation here, and I encourage you to take a look at Karai17's Lapischan, both of these are excellent resources for learning what Lapis can really do.
a Perl/CGI program that lets you access IRC from a web browser
[http] posted by m455 on July 05, 2022
reference for escaping characters in xml documents
[https] posted by m455 on July 05, 2022
Harder Drives (includes how to use ping has a block storage device)
[https] posted by kindrobot on July 03, 2022
[https] posted by dozens on July 03, 2022

🌱🦛
linkbud went on too many dates
[https] posted by m455 on July 01, 2022
I'm never not going to post this
[https] posted by acdw on June 29, 2022
Databases and like, complicatedness
[https] posted by acdw on June 29, 2022
I read this post by Baldur Bjarnason, listing "Everything I’ve learned about web development in the almost twenty-five years I’ve been practising", and this followup, which says:
Some of the aphorisms ended up not-so-pithy, but it was overall a fun little experiment that I recommend: note down everything relevant about the craft that you can think of over the space of a week.
I thought about this, and then I thought: Ok, what exactly is my craft? I do computer shit. So I started a list about that, challenging myself to be descriptive about things and not veer too far into pure advice.
A year or so passed, and I noticed this post was still sitting in my "work in progress" directory. I tried picking it back up and noticed how much overlap it would have with other posts like these:
This style of writing is basically catnip to people like me, whether it's of much use to anyone else or not. This post ultimately felt like a dead end, because instead of a blog post, it really wants to be some long document where I collect all sorts of aphorisms, pithy quotes, eponymous laws, and so forth about technical work and maybe just work generally. Maybe I'll start that document one of these days.
✯
Anyway, that very partial and uneven list:

In reply to: Oatmeal - That one time when Buffy the Vampire Slayer maybe saved my life?
After giving my brain bleed time to heal the neurosurgeon called me back in to hospital; the plan was to reassess, attempt to fix it using the minimally invasive technique that they tried once before, and if that didn’t work, do something a bit more squidgy directly in my brain.
I’ll be honest, the last option sounded totally and completely horrific to me and I was very much not wanting to have to go with the big ol’ brain surgery. While the doctors seemed confident with that option, they were upfront about the extra risks and that it was sort of the option of last resort.
Last week I went back in and, great news, they think they’ve totally repaired my brain bleed using the minimally invasive method! I’m slated for a diagnostic scan in the fall to double check, but, so far, everything is looking great. I spent a few more nights in ICU and was discharged directly to home where I’ve been chillin’.
All in all I’m feeling super duper lucky, and, while this entire experience has been … let’s say a drag … I know that it could have been far worse, and I hope to have it completely behind me soon. So far the main symptoms I’ve faced are ringing ears, fatigue, a bit of difficulty focusing and multi-tasking, occasional low grade headaches, and, since the repair, I’ve developed a lisp. The lisp is a result of the repair itself, and the neurosurgeon thinks that it will probably pass within a few months.
There are too many people to thank directly here, but to all those who’ve supported me and my family throughout this bananas unexpected experience — for realizes — thank you so much. The words of support, well wishes, meals, help with kids and everything have been so deeply felt, and I honestly can’t imagine how I would have navigated this without ya’ll.
Hopefully this is my last health update for a long time, and I can go back to posting about forth now!
Mipui - open source collaborative grid map editor for tabletop games
[https] posted by mio on June 25, 2022
Start all of your shell scripts with a comma
[https] posted by m455 on June 24, 2022
directly query csv with sqlite
[https] posted by dozens on June 22, 2022
trash cat (they/them) and Juliana (she/her) talk about Matrix. Part 2 of 2.
trash cat: You're listening to trash cat tech chat, a Librepunk podcast.
tc: If you want to know details about the cryptography, listen to the extra thing. But I want to talk about from a user perspective, what is it like using the cryptography, and how do we verify other users, and things like that.
Juliana: Yeah. Obviously, it kind of starts at account registration 'cause that's when you, you know, initially create your identity, and by default, I think, everything is encrypted but not necessarily verified? I'm not sure exactly what the difference is.
tc: Um, so, I think I know what you mean, but I want to give a little bit of clarification for the audience. What you mean, I think, is conversations that you have, messages that you send to other users in private rooms by default are encrypted.
J: Yes. Which, for context, is the main... Most of the time I have had Matrix open, it has been for that purpose, regardless of client or whatever.
tc: Yeah. So if you just like, start a new room with someone, most clients, at least Element, by default will make it encrypted, and you just don't have to do... You don't have to take any extra action to make it encrypted. It's just encrypted by default.
J: And if you're in a room that's not encrypted, and you want to start it being encrypted, or if you want to verify an encrypted room, whatever that means, you can initiate a... I guess you'd call it a "handshake". A verification session where you basically--
tc: I wanna um... Small correction there: It's not... Okay, so there are two things going on that I think you're talking about, and one of them is there are rooms... Okay, so there are rooms and users, and those are different entities, and the way that we're going to interact with them is a little bit different and important to talk about. Okay? So...
J: Okay.
tc: And sorry for interrupting you, but like...
J: No, yeah, I would rather you make sure we're saying the correct things. I mean, I... Part of the problem is, my clients are all in French, so I don't necessarily know exactly what's happening.
tc: [laughs] Okay uh... So there are rooms. Everything on Matrix is a room. Kind of. In the sense that you have chats with individual people, like direct messages you might think about them as, are a room with the two of you in it. And group chats are also a room, just with more users in that room. So a room is kind of the basic entity of like, "Here's where a conversation is happening." Rooms can be either encrypted or unencrypted. By default in major Matrix clients, by which I mostly mean Element, but also FluffyChat, I believe, does this. By default, when you make a new room, and it's a private room, which includes either a quote-unquote "DM", direct message where like, it's you and one other person, so like, Alice and Bob together in a room that's just a private chat with them, or when you're making a room, you can mark it as private or public. By default when you make a private room, it will be encrypted. And you can also -- in a room that's not encrypted, you can turn on encryption, which is just like, a little toggle in the menu that says, "This is going to be encrypted from here on." I said something earlier when we were talking about XMPP like "I wanna talk about this later." One of the things that's interesting and noteworthy to me about the difference between XMPP and Matrix is at what level the encryption is specified. I think that's the way I want to phrase that. So in XMPP (and probably other things, I don't know) -- In XMPP, if you and I are having a conversation, there's no real, like, concept of a room. There are multi-user chats, which exist as like a room-type thing in XMPP, but if you and I are having a conversation, it's just like, my device is sending a message which then will get delivered to your device or devices on either or both ends. And I can enable encryption at the device level. So I can say, "Okay, I want messages sent from my device to your device to be encrypted. But it's not, like, sort of specified on the server anywhere that "Oh, this conversation happening is encrypted." It's just I am sending messages that are encrypted. With Matrix, it's like, an actual variable of the room that says, "This room is encrypted."
J: That is an interesting distinction.
tc: Yeah. I'm not sure I have anything to say about it further than that. [laughs] But that is, that's how it works. The room... In Matrix, the room itself is encrypted or unencrypted. And if it's encrypted, then all clients are at least supposed to send encrypted messages in that room and not send unencrypted messages. So that's the first thing is "Is encryption on or not?" And then the second thing, which is what you were trying to talk about when I interrupted you, is verification, which is a separate matter from "Is the room encrypted?" And verification is... So basically, there's this big problem in cryptography. I think I talked about this... Yeah, I talked about this in the first episode with like, trust on first use and stuff. But there's this big problem in cryptography that is: How does Alice know she's actually talking to Bob? How does Bob know he's actually talking to Alice? And the answer is: At least in the context of Matrix what they do is they verify each other. Alice and Bob, out of band, in some, like, trusted -- ideally in-person they meet up and compare numbers. They compare their identity keys to say, "Is the entity that I'm talking to digitally who claims to be Bob actually Bob? Is -- actually the person that I meet up with in-person that I know as Bob? And vice versa with Alice. And this is done on a per-user level. Mm, let me... Sorry, there are two things taht I want to say about that. [laughs]
J: Go ahead.
tc: I introduced you to talk, and then I'm just doing all the talking. But, uh... [laughs]
J: I'm sorry that I don't have a better understanding.
tc: It's okay! It's uh... But um, okay, so... Alice and Bob want to verify each other. So, in a system like XMPP, what this looks like is each of Alice's devices, each device has its own keys. It has its own identifier. And if, say, Alice has, you know, a laptop and a phone and a desktop computer, and Bob has a laptop and a phone, and they want all of the devices to be able to talk to each other, they have to -- and have that strong verification, they have to pairwise verify each pair of devices. So Alice's desktop to Bob's laptop, Alice's desktop to Bob's phone, Alice's desktop to Alice's laptop, Alice's desktop to Alice's phone, and so on. Every pair of devices needs to verify each other.
J: Okay.
tc: In like, OMEMO, in XMPP land. And that's terrible user experience. But that's the basic idea is they meet up, and they say, "Okay, you know, do these numbers match up?" And if they do, we mark them verified and say, "Okay, we know that we are actually talking to each other." But it's a terrible user experience to have to do it manually. When Bob gets a new phone, suddenly Alice has to re-verify that device from all of her devices, each individually, and also Bob has to verify his new device with his old devices. And um... it's just a whole mess. Matrix does this really nice thing in this area, which is called "cross-signing", which basically... When Alice starts... So, when Alice like, opens her first device on Matrix, whatever. Say when Alice starts running her second Matrix client, so she already set up on her laptop. Now she's setting up on her phone. Her laptop will ask her to verify the new device. And so she does that, and they do the cryptographic key verification -- which, I do want to talk about how that works, but right now I want to talk about like, what does it mean? They do the cryptographic device verification, and then Alice has verified that her own phone is the same device as her -- Sorry, they verify each other. Both devices verify each other. Alice has verified that her laptop and her phone are run by the same person, and when Bob goes to verify Alice, he can verify one of her devices as being "Alice" -- so, essentially, instead of verifying individual devices, you're verifying people. Bob verifies "Alice" as the owner of the laptop and by extension her phone. And then if Alice gets a new device, her -- say, adds her desktop as well, she verifies her desktop with one of her devices (she doesn't have to do it with all of them), and now her desktop is trusted by her other devices as part of the same identity, and by extension, Bob, and whoever else have already verified Alice's identity, can trust Alice's computer -- her desktop -- without any additional work. It's a much simpler, much easier system where you just, you verify users rather than individual devices, and you trust a user to manage their own devices properly, and it makes everything so much easier to use than, like, XMPP is.
J: Yes.
tc: So just to clarify, like, the difference between how you interact with users and how you interact with rooms... It's a little bit confusing because sometimes they look like the same thing in the interface, in particularly when you have, um -- [sarcastic] "in particularly" -- in particular when you have a DM, so to speak, a private room with just you and someone else. But, and I think this is important, what you're actually doing when you enable encryption is you're setting it for that room. Even if there are other rooms with that person in them, those might still be unencrypted. But just that room gets encrypted. And what you're doing when you're verifying is you're verifying the user, rather than the room. And so, you might be in a room -- Say, Alice, Bob, and Carol are all together in one room, and separate from that, Alice and Bob have another conversation that they're together in. Alice and Bob have verified each other, but Alice has not verified Carol. So, in the room with Alice, Bob, and Carol together, they can still use encryption, and Alice will still be verified with Bob within the context of that room, but they won't have that level of ver-- Alice won't have that level of verification with Carol. Does that distinction make sense?
J: Yes, it does.
tc: Okay.
J: The interface to do this, to verify devices to each other, to verify users, to, you know, do all this, looks very similar, and it's very easy for a user to do. You just like, so when you log into a new device for the first time, you will be asked to either use a copy of, uh... I don't remember the exact terminology, of a key that you can download through a client.
tc: The uh, in English, what it calls it is "Secure Backup".
J: Yes. You can use that to verify a device, or you can scan a QR code. So that's how I've mostly been doing it lately. Or you can do the emoji thing, which is where it shows you a list of emoji, you look at the emoji and see if they match, and if they do, you confirm on both devices that they match.
tc: Yeah, and emoji verification is really nice. In like, XMPP/OMEMO land, we have scanning QR codes. That is a paradigm that exists. But if you're not in a situation where you can scan QR codes, you have to manually compare hexadecimal strings that represent public keys. And that's not a good time. But the other thing about that is with XMPP, because we don't have the cross-signing, and because we don't have the... all the various features that are nice with Matrix, with XMPP, you have to do both steps in the verification, by which I mean if Alice's phone and Bob's phone want to verify each other, Alice's phone must verify Bob's phone, and also, Bob's phone, which has a different fingerprint for verification, must verify Alice's phone. That wasn't the right way of saying that. Alice must verify Bob's fingerprint, and also, Bob must verify Alice's fingerprint. It's a 2-step process. Matrix simplifies it into a 1-step process, right? where you scan a single QR code that represents both parties, or you compare a single sequence of emoji that represents both parties, and then you've done both steps of the verification, rather than having to verify two different numbers.
J: Yes. And this simple interface is used for everywhere that user verification is required, so it's super nice.
tc: One complaint I have about Element and cross-signing and everything is the Element... the ability to do cross-signing is not exposed in a way that allows it to be done offline. So what that means is, if I -- So in, say, XMPP for example, let's say my only computer is a desktop computer, but I still want to verify with someone by meeting up in-person. Well, I can write down my fingerprint and then show it to them, and they can say "Ah yes, I believe that this is you." You can do that in Matrix, but only per-device. You cannot do that with the cross-signing key. At least with Element, there is no interface to manually verify a cross-signing key, which is really obnoxious. [laughs]
J: That is interesting. I hadn't thought about that. But yeah, that makes sense.
tc: Like, there's no reason it couldn't be an option, to be clear. I mean, there's no technical reason you shouldn't be able to just write down your cross-signing key -- the public key -- and then show it to someone, and they open up a thing and say "Yes, this matches. I want to sign this cross-signing key" or whatever. There's no technical reason it can't be; it just is not implemented in a way that allows you to do that.
J: It's kind of a shame.
tc: It is. I hope that they fix that at some point.
J: I'm trying to think if there's anything else I want to say about the sort of user interface to this.
tc: At one point, I don't remember if I included this in the first episode or not, but you said when we were having that conversation, you talked about the -- I think I cut it -- you talked about um -- you said you like that it's... that it has both encrypted and unencrypted rooms, and you can enable encryption later from a room that starts unencrypted. Would you like to talk about that?
J: Yeah, I guess so. So basically, the reason I like that is that a lot of people are not going to go out of their way to have encryption. So if I were to say, "Hey, talk to me on this encrypted chat app", they might think "Oh, encryption. This is going to be, you know, complicated, a pain in the butt. I don't want to do this." Whereas if I say, "Just make an account and talk to me on this thing", they're not gonna have that pre-judgement that it's gonna be complicated. And then, because it actually makes encryption -- comparatively at least, I mean -- simple, it allows you to just like, start it up. Like, you could just be chatting with them one day and hit the button, and then they don't have to know what's going on. You hit the button, and you can just be like, "Oh yeah, we're just verifying each other, and badda-bing badda-boom, you have encryption." It's a good way to avoid intimidating someone before they come into an encrypted chat, you know, situation.
tc: Yeah, I get you. I do wanna clarify again, just that -- the difference between encryption happening in the room and verification. Like, those are different things.
J: Yeah. So, I had a misunderstanding on that because I was using Fractal so much, so most of my rooms were not encrypted. And then when I switched to Element, I had to activate encryption on them, and to do that it requires you to verify at the same time.
tc: On Element? It shouldn't require verification to turn on encryption.
J: There was something I had to do. Or, maybe it was just that the other person had to agree to turning on encryption.
tc: I don't think that's... right either. I think just anyone with like, admin permission or whatever level in a room can unilaterally enable encryption for the room, and then it can never be turned off again for that room. And like, that's the way that that works. And like, verification is good and everything, but it's not... Like, most rooms in Matrix, unless they're intentionally big public rooms, most rooms in Matrix are -- not with Fractal, but with Element or whatever -- are going to be encrypted, but you probably haven't verified the other users 'cause that's like, the default state.
J: That's interesting. I wonder what was happening then. Huh.
tc: I don't know... That's okay, though. [laughs] But yeah, you don't need to verify the people in a room to have an encrypted room, but without verifying them, a malicious server or something could just drop an extra device into the list of devices and then start reading your messages.
J: Gotcha.
tc: Yeah. Okay, anything else about the experience using encryption, cross-signing and everything... Anything else about that before we move on?
J: I don't think so.
tc: Okay.
tc: So, just very briefly I want to acknowledge, because in our first episode I talked about Signal getting funding from the Open Technology Fund, OTF, I want to acknowledge that libolm was audited in 2016, like I mentioned before. That audit was funded by the OTF as well. That's the entirety of what I had to say on that matter. I just thought it was worth mentioning since we talked about that.
J: Yeah.
tc: Cool.
tc: So then, the next thing I wanted to talk about was: What are some issues with Matrix? Both in terms of privacy and in terms of user experience, whatever, what are some problems with Matrix?
J: Well, as our recent discussion may have shown, it's not exactly transparent everything that is going on.
tc: Yeah, it's a little unclear sometimes. [laughs] And like, I think part of that also is just Matrix is so complicated. Like, if you try to follow development at all, there's a lot going on in the space, in Matrix specification development and in all the different pieces of software that do things related to Matrix. It's just really complicated.
J: Does it need need to be that complicated to have the kind of features and functionalities that it does?
tc: Um... I don't know. I don't know enough about it under-the-hood to really answer that question. One thing I can say personally is I don't care about all of the features that it does have. I would personally prefer something that's simpler and more just focused on privacy. But that's me, and that's not representative of everyone who uses or likes Matrix. I know a lot of people like a lot of the things about it, the ability to have large public rooms and bots and stuff like that.
J: Yeah, I would tend towards your side on this too. I don't use like, voice chat. I don't use video chat on it. I might in the future because it's there, and that's convenient, but it's not the primary reason I'm using it. Large rooms are cool, again, because it's there, kind of, but if it were not... So, the main reason I'm involved in rooms is for projects I've collaborated on or like, communities I've been active in. So I'm in the Raspberry Pi room. I would probably not start a room myself just because that's not the chat paradigm I'm most comfortable with. I like talking to people one-on-one usually.
tc: Yeah, same for me.
J: And this ties in, I think... Honestly, from a user experience perspective, at least, I think Matrix's greatest weakness is it's trying really hard to be Discord, and I don't think that's necessarily a good idea.
tc: I also feel like in general it's trying too hard to be everything. Like Matrix wants to adverti-- I mean, okay, so part of this is like, Matrix wants to advertise itself by all of the benefits of it, some of which are mutually exclusive. So like, Matrix wants to be known as, for example, a private messaging platform. Right? You have the end-to-end encryption, you have all the cool stuff there. Matrix also wants to be known as the one place to do all of your communication because you can bridge everything else to Matrix. But, as discussed before, those two things are incompatible with each other. You can't have both end-to-end and a bridged roo-- Sorry, end-to-end encryption and a bridged room from like, Matrix to Discord or whatever. And I feel like there's... Like also, if you look back at previous Matrix things, I think people... Like, Matrix didn't even used to be identifying itself as a chat platform as the primary thing. It was like, "This is a protocol for being a store of information" or something, "and it can be used as that for instant messaging." I don't know, I feel like there's just... There's so much going on that it wants to be, and there's a lot of stuff built on Matrix that um... Like they're working on... There's some social media platform that's in the works that's built on top of Matrix or something like that, and...
J: What?
tc: Yeah, I'm trying to remember what it's called. I don't know. I think Krille Fear, who's the developer of FluffyChat, I think is involved with that, and there's an effort to bring stories functionality to Matrix.
J: Oh no.
tc: And like, all kinds of other things. I feel like Matrix wants to be everything, and I don't think that that's a good thing, personally.
J: Yeah, I mean, I agree with you. I think this is... I saw someone talking about this the other day. Not everything needs a story, right? They were talking about, I think it was Duolingo has implemented a stories functionality, and it's like... Everything is trying to be social media now, and not everything needs to be social media. But because Matrix is trying to appeal to a mainstream audience, and, you know, these big products that everybody knows, Snapchat, Instagram, you know, whatever, have these features, it's something that most people are going to come to expect. And so in order to be a mainstream platform, Matrix has to look like all the mainstream platforms, and I think that's to its detriment.
tc: Yeah, I agree. Some other issues with Matrix -- if you're okay moving on from the "Matrix tries to be everything"?
J: Yeah.
tc: Okay, some other issues that I have. Like, the whole idea of "store everything forever", basically, is not something that I want. Actually, what I would want is by default everything to be ephemeral, and then optionally you can make things longer-lasting if you need to. Matrix, as far as I'm aware, still doesn't have any real mechanism for ephemeral messaging. You can delete, i.e., redact old messages, like existing messages, manually, but I don't think there's any way to have self-destructing messages or anything like that.
J: Yeah, that would be a good thing to have. And it's interesting. The storing everything forever makes sense now when you mention that it was originally a store of any data. That's interesting but also not a great basis for a secure chat platform.
tc: Yeah. And like, I mean, I run an XMPP server, and I run a Matrix server. And like, one of those, I have to worry about like, "Oh, what if this", you know, "takes up too much space on my server?" And the other one -- XMPP, again, doesn't even store things long-term by default. You have to like -- I mean, all the modern clients tell it to do that at this point. But you have to enable settings. It's mod_mam, the message archive management. You have to enable message archive management to have your messages stored temporarily, and the reason you do that is for like, multi-device syncing purposes, not so that you have a long-term history on the server. HTTP fil-- Well, okay, I should step back. With XMPP, the way that files are usually implemented is you upload the file to the server where it gets stored in a specific place that it's accessible. Whatever. You upload the file to the server, and then you send a link to the file as an XMPP message to the recipient, and then their client downloads the file. Those files... And I'm speaking from the perspective of I run a Prosody XMPP server. That's what I'm used to. I'm not sure what ejabberd does. But those files get purged regularly by default. I think they only exist for like a week on the server by default, and then they get deleted. I think I have my server set to delete them after 48 hours because generally everyone's online all the time. Like, your phone is going to download the image or whatever I sent you in most cases within a few hours, at least when it's back online if it wasn't online. It doesn't need to be stored on the server after that.
J: Yeah.
tc: So I would prefer, both as a server operator and as a user of Matrix, I would want it to be much more ephemeral.
J: Yeah, I think that's -- at least having the option for that is a good idea.
tc: Yeah. And then one of the other things there, right? is you have like, if I'm on homeserver1, and you're on homeserver2, and we're in a room together... the basic model of Matrix is every device, every client and every server involved should sync the entire history of that room. So my devices, my server, your server, and your devices should all have a redundant copy of everything. You've got so many different servers -- in big rooms, you might have a bunch of different servers all participating in the same room, all duplicating the same data across everything.
J: Yeah, I think it's a question of the model, I guess, of who has -- who is the -- what is the source of truth, I guess, for the record? Right? Whose job that is, whether that's the server or the client, I guess.
tc: Yeah. And then because you've got all this data that's stored long-term and synced across everywhere and whatever, that requires as a server operator you to collect and store lots of metadata on all your users. Even if the messages are encrypted, you -- because of the way Matrix works, you effectively have to have records of every time a message was sent, from whom, to whom, etc. I wanna clarify a little bit: There's something in Synapse that you can do to try to auto-expire old messages. I've never been really clear on how effective that is, but I have mine set to auto-expire old messages after like, maybe it's a month, maybe it's longer. I don't remember. And I think, like I've seen in my client those go away after a certain amount of time, old messages. So there might be something like that that does kind of work, but it's, like, by default, I think you store things for at least a year. And it's, I don't know, not what I would prefer.
J: I wonder if that might be -- So, okay, I look -- I feel like both of us are very interested in systems, and we're interested in slightly different systems. A big system for me is socials. Like, I'm a programmer. I'm interested in application development. I'm interested in how computers can help people talk to each other, get along, do things, right? And so, I'm interested in the intersection between the system of security and the system of society here. And so, I'm asking myself if perhaps there is like, a government reason -- a government regulation that would require a government using this platform to keep messages for that amount of time, and then that would be why Matrix would make this decision so that it is compliant for any potential government clients.
tc: That would make sense, but I mean... That makes sense. That's probably at least part of it, and I know there are governments interested in using Matrix. Like, the German government is doing this initiative to get its medical communications infrastructure on Matrix or something like that. Actually, since I talked about funding before, the vodozemac, however that's pronounced, the Rust crypto library for Matrix -- the audit of that was funded in part by the German government as part of that initiative.
J: Oh, that's super cool.
tc: Yeah, so that makes sense to me, but I think it should be optional and easier to configure at the server level, you know?
J: Yeah, a government actor is gonna have a lot of resources to make redundancy possible.
tc: Yeah. So, I feel ways about that. And... Like, with XMPP, you can argue, "XMPP creates a lot of metadata as well!" or "[insert given chat thing]"
J: Yeah, I mean, if you're wa-- I mean, fundamentally, if you're watching network traffic, you're going to be able to get a shit ton of metadata anyway.
tc: Yeah, absolutely. But there's a difference between sort of at the protocol level essentially mandating that you store all this metadata, versus having the ability to store it and also having the ability not to store it longer than it's needed.
J: Yeah.
tc: Anyway, so that's a whole thing. Another thing I think is worth talking about is the whole centralization of the network. And it's hard, I think, to find... It's hard to not go with matrix.org, I feel like. All the major clients default you onto matrix.org...
J: Yeah.
tc: ...and then there are, like, lists of other servers that are -- that you can use. And you can run your own, but Synapse is not a good time, so it's not great running your own as an experience, so you generally end up wanting to use someone else's. And then like, "Which ones are good?" Well, matrix.org is kind of the only real recommendation you get from like... from Element or from FluffyChat or whatever. So if you go looking for other things, like, there exist some lists. How do you know which servers are good? Some of those lists are run by... let's say, right-wing-aligned people who... There's one list in particular that like... It describes some, I mean, it's -- it promotes like, right-wing servers like Kiwi Farms and stuff.
J: Oof!
tc: Yeah, but it like, it's very clearly written with a right-wing lens... like, extreme right-wing lens, if you know about any of the things that it promotes and can like, read between the lines. But one of the things that it says on this site is um... It has a little badge for servers that are... What's the phrase they use? It's like "certified" by matrix.org or something like that. And what they mean by that is servers that matrix.org has blocked because of like, abuse or whatever reasons.
J: Wow. That's...
tc: But if you don't know that, if you just pull up a random list, it looks like "Oh, these are good servers to use." And I have had a friend share this link with me and say, "Oh, look, these ones are recommended by matrix.org!" or whatever, and like... and I had to be like, "Yeah, okay... No." [laughs]
J: For those who don't know, I just want to mention this real quick, Kiwi Farms is an anti-trans hate group that works through the internet to bully trans people and has a body count.
tc: Yeah. And um... halogen.city is one I think we need to talk about because it's extremely not apparent if you just look at it. There's a server called halogen.city, and if you go to it, it's like, "Here's a cool cyberpunk background. Here's some basic information about the server." It looks really nice. For a while, I was recommending it to friends because I was like, "Hey, this looks nice. It appears to perform well." Whatever, like, what more do you need? And part of this is I think about it as, you know, I think of Matrix as being for one-on-one conversations, encrypted messaging. So like, it doesn't really matter that much which server you're using... from my perspective. But then like, other people, for whom that's not the primary way of thinking about it, they look at what rooms are available, and halogen.city lists a lot of like, right-wing, like, Nazi rooms and stuff like that. And like, oh, well, I didn't know this. I will stop recommending that to people. But it's like... it's not apparent. And you can go looking through the rooms that are publicly listed by a server, but it's not obvious. My point here is that choosing a server is hard, but also matrix.org, which is the default choice in like all cases is not a good choice. And I don't know how to reconcile those things.
J: Yeah. There's even, when I was looking into setting up a Matrix server of my own, I came across discussions where people were talking about, you know, you might have a deployment like matrix.org that has, you know, thousands of rooms, some of which have tens of thousands of participants, and it's like, that's not practical for most people to kind of keep up with.
tc: Yeah, absolutely. Like... [disgruntled sound] Yeah.
J: But then, at the same time, you run into issues. The other night, when my friend was trying to set up an account, she was gonna set up an account on a friend of a friend's server, and it didn't support email verification, or like, putting in an email so you can recover your account. And that was a deal-breaker for her, so she had to use matrix.org.
tc: Another thing -- this might have been -- this might be what you just said like a point ago -- if you're running, like if you're on some third-party... I hate to use that phrase, but like, matrix.org and not matrix.org. If you're on some non-matrix.org server that's just run by like, a person, you may not be able to join large groups. They may have disabled it -- like, the homeserver administrator may have disabled it. There is a setting in Synapse to uh... How do they say it? It's like "Disallow rooms above a certain complexity" or something like that. They may have disabled it, or it may be that if you just do this action, it will cause everyone on the server to have a terrible experience. If you just try to join like one of the big Matrix rooms or whatever on matrix.org. So you may kind of have to use matrix.org for those big rooms because otherwise it'll like, bring down your server or something. It's... [sighs]
J: It's a frustrating situation. And I feel like if you had ephemerality of communications by default, that would not be as big of an issue.
tc: Right, if you didn't have to sync everything when you first connect to a room. [laughs] Yeah.
J: Also just deployment in general. So, it's federated, which means that it's theoretically possible to talk with anyone from any server, but there's a barrier to entry in the complexity of setting up and administrating a server. And from looking at it, it is not the most complex thing out there, but it is definitely not the simplest, so...
tc: It's non-trivial, yeah. I don't know, I don't like running a Matrix server. [laughs] And I have run Dendrite in the past, and that was like, okay, but it's not complete. Like, performance-wise, it worked well at what it did. And this was a year or more ago, I think, so it probably has come a long way since then, but... And then you have like the relationship between Synapse and Dendrite where the developers keep doing more and more work on Synapse which makes it harder for Dendrite to catch up to Synapse so that it can become the new standard, the new reference.
J: Yeah. And I think that fact, all the development that is going on continuously is also probably part of why, you know, those two -- both of those servers are made by the Matrix project. There's no third-party implementation of a Matrix server. All of these clients that are missing functionality, part of it is development goes so fast that it's hard to keep up.
tc: Yeah, exactly. I think there are projects that are trying to do third-party Matrix servers, but they're like... they can't keep up, so like... I don't think there's anything complete enough to use... [laughs]
J: Yeah. And so protocols like IRC are-- which, obviously not by default encrypted; you have to do external stuff for that -- or XMPP or whatever, it's older. It's stable. People know what they're getting. You know. You can use the same, like, plugins that you've been using for 10 or 15 years, and it's no issue.
tc: And they were written in a time when people tried to write good software.
J: Yeah. [laughs]
tc: Like, running Prosody on a server (Prosody, XMPP server) is nothing, you know? It's really easy to do. It's technically not very difficult to set up, and it's really lightweight when it runs. There are a lot of XMPP clients that are very lightweight. They may not be as, you know, beautiful and Discord-like and whatever as Matrix. They may not be as appealing to that crowd. But like, I don't know. I really -- It's probably extremely obvious, but I really like XMPP and-- a lot more than Matrix. [laughs]
J: Yeah, and I mean, especially for using it as a one-on-one chat platform, and Matrix just adds a lot of overhead that isn't needed for that use case.
tc: Yeah. And like, I'm not gonna get into the whole thing, but -- go listen to the cryptography extra thing, but Matrix does this more complicated cryptography thing so that it can scale better, but it does that in all conversations, in all encrypted rooms. Even if it's just two participants in the room, it still uses the more complicated, less secure (I'm gonna say), but more scalable thing because it's so focused on like, "This is a room" rather than this is a one-on-one chat versus a group chat or something.
J: Yeah.
tc: I don't know.
tc: So, what is ultimately your conclusion, your takeaway? How do you ultimately feel about Matrix?
J: Honestly, I feel like in situations where you need a group chat platform, and you want to use -- and you either want encryption or free software or both, it's just kind of your only choice, and um, that's a shame, but it's better than Discord, is what I always say.
tc: Yeah. I mean, you can do it with XMPP, but it's not optimal with XMPP multi-user chats. I don't disagree. [laughs]
J: Yeah.
tc: I kind of think personally -- and I said this when we were recording the first episode, but it was part of the stuff that I cut -- basically, my take with Matrix is there's a lot that I dislike about it. There are a lot of issues and generally a lot of things that I... basically wish it was XMPP. But ultimately, at the end of the day, I think it meets this intersection of like... being decent, good enough at all the different things, which nothing else really is in that intersection. Like, Matrix... I don't like the clients, but they're usable. They're not bad. I take issue with Electron, but like... they're usable. People would probably be okay with them. There are some things that are a little unintuitive, but for the most part, like... it's not too bad. As a network, yes, it's very centralized on the matrix.org server, but it is federated. You can run your own server. You can join a friend's server. Whatever. It has its cool crypto stuff going on, which I like. Cryptography, to be clear.
J: [sarcastically] Whoa, really?!
tc: [laughs] Just, you know, I always feel like I need to clarify I'm not talking about cryptocurrencies. And unlike some other messengers, this thing does not incorporate a cryptocurrency into it, at least last I checked.
J: If it does, we will find something else.
tc: Yeah, that would not be good. Yeah, so you have reasonable level of privacy there with at least you get end-to-end encryption with forward secrecy and it's-- with deniable authentication, and like... the things you want. It has, uh... You can use it anonymously. You can sign up without any identifying information. Especially, depending on the server, some of them... I mean, it's per-server. They choose what they want to require. You can use it without a phone number. But also, you can optionally sign up... it's like, the vector.im, I think, service, but there's a service you can use to list you -- yourself on a registry based on your phone number or email address or whatever, so that people can automatically add you, which I don't -- I mean, I understand that that's a thing that people like, being able to kind of bootstrap their network of friends on a new network. I understand that that makes it a lot easier. That's not how I personally interact with things, and I like that there's the choice for that. I feel like I'm forgetting important things. It's free software. It's, you know, all that stuff. So I feel like it's not, like, the best at anything, but it's generally good enough all-around, and I think that this is the thing that might actually be, like, usable and friendly enough that people actually -- normal people might actually want to use it.
J: Yeah, exactly.
tc: So, in this conversation about messaging, which is very much influenced by network effects. What are -- What people are using is what is useful, right? In that conversation, I think that Matrix plays an important role because I think it has a lot of potential to get people actually using it in a general sense, not just for niche use cases, and consequently, I think it's an important project.
J: I think that's a very nuanced and thorough analysis of the situation, and I agree.
tc: I also feel like it's worth mentioning that you and I arranged to talk on this show using Matrix. I mean, we've been talking on both Matrix and the Fediverse, but... we are both Matrix users...
J: Yes.
tc: ...and we have been using that with each other for this show.
J: And it's my main chat platform. It's -- I've managed to get all but one of the people I talk to regularly onto it, and as soon as I get that last person on there, I am deleting Discord forever!
tc: Nice! XMPP is still and probably will always be my primary thing, but Matrix is overall, I think, good. Despite all the many complaints I have with it, overall, I think it's good. And I think that's where I'll leave that.
J: Yeah.
tc: You've reached the end of this episode of trash cat tech chat. Check out the show notes for links and other information. This podcast is licensed under a Creative Commons Attribution-ShareAlike 4.0 license. Music by Karl Casey @ White Bat Audio.
Music by Karl Casey @ White Bat Audio
Running Doom on a chip from a $15 smart lamp
[https] posted by mio on June 21, 2022
Old-school blogging, retro computers, and decentralisation
[https] posted by m455 on June 20, 2022
{kind=link}
{kind=link}
{kind=link}